ich habe erst vor ein paar Tagen angefangen ein Python-Skript (Webscraper mit Beautifulsoup) zu schreiben und würde gerne eine Benutzeroberfläche hinzufügen.
Was die Benutzeroberfläche können soll:
- Ich möchte zwei Werte angeben: Checkbox Ja/Nein oder 1/0 und ein Feld in dem man eine Zahl eingeben kann. Diese beiden Werte sollen im Skript berücksichtigt werden.
- Ich möchte das Skript mit einem Button "Start" starten können und mit einem Button "Stop" stoppen können.
- Die Ausgabe (Prints) soll in der GUI in Echtzeit angezeigt werden.
Ich habe dazu ein ähnliches Beispiel mit PySimpleGUI gefunden:
https://pysimplegui.readthedocs.io/en/l ... ent-window
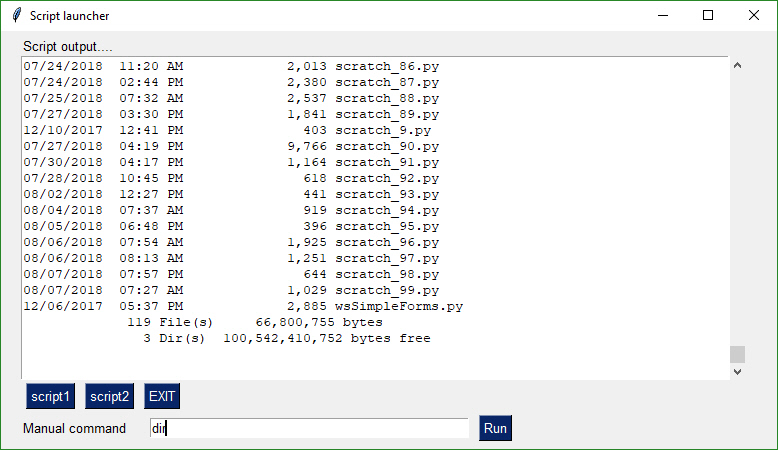
Im Endeffekt möchte ich etwas ähnliches erreichen. Jedoch mit einer Checkbox, einem Inputfeld und zwei Buttons (Start/Stop) und die Ausgabe des Skripts soll im "Script output..." passieren.
Ich verstehe jedoch nicht, wozu das Modul "subprocess" benötigt wird und wie ich mein Skript mit einem Button starten und wieder stoppen kann und die beiden Werte in Variablen speichern kann.
Mein Skript sieht momentan folgendermaßen aus:
Code: Alles auswählen
from bs4 import BeautifulSoup
from multiprocessing import Pool
from time import perf_counter, sleep
import requests
import json
import re
import webbrowser
import lxml
open_webbrowser = 0 #Legt fest, ob der Webbrowser automatisch bei einem Treffer geöffnet werden soll (1=Ja, 0=Nein)
process_limit = 8 #Legt die Anzahl gleichzeitiger Prozesse fest
headers = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/77.0.3865.120 Safari/537.36',
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3',
'Accept-Encoding': 'gzip, deflate, br',
'Accept-Language': 'de-DE,de;q=0.9,en-US;q=0.8,en;q=0.7',
}
proxies = {
'http': 'socks5://127.0.0.1:9150',
'https': 'socks5://127.0.0.1:9150'
}
def scrape(list):
*Hier werden die Links aus der Liste gescraped*
*Wenn eine Bedingung erreicht wird, soll ein Webbrowser mit dem Link geöffnet werden. Dazu die Einstellung open_webbrowser*
if __name__ == "__main__":
while True:
with open('list.json', 'r') as f:
list = json.load(f)
print('* Liste geladen *')
start_time = perf_counter()
p = Pool(process_limit)
p.map(scrape, list)
p.terminate()
p.join()
end_time = perf_counter()
execution_time = "{:.2f}".format(end_time - start_time)
print('- Dauer des Durchlaufs: ' + execution_time + ' Sekunden')
Vielen Dank.
Chris87

