Hallo,
habe folgendes Problem.
Bin seit ca. 1 Woche mit Python am experimentieren und habe sehr gerne html requests an bestimmte Seiten geschickt und das einwandfrei.
Seit heute klappt es nicht mehr ich verschicke den Request und nichts passiert. Es scheint wie aufgehangen, es erscheint kein Fehler und ich bekomme keinen response .
Hat jemand Ahnung was es sein kann bzw hatte mal das gleiche Problem?
HTML-requests ohne Antwort

Bitte zeige deinen Code, was passiert und was du stattdessen erwartest.
Du rufst doch auch nicht in einer Werkstatt an, sagst dass du seit einer Woche Auto fährst und heute morgen nichts passiert, als du den Schlüssel ins Zündschloss gesteckt hast, um dann zu fragen, ob die mal ein ähnliches Problem hatten.
Du rufst doch auch nicht in einer Werkstatt an, sagst dass du seit einer Woche Auto fährst und heute morgen nichts passiert, als du den Schlüssel ins Zündschloss gesteckt hast, um dann zu fragen, ob die mal ein ähnliches Problem hatten.
-
panikgurke
- User
- Beiträge: 3
- Registriert: Samstag 28. Dezember 2019, 02:00
Hier klapptssparrow hat geschrieben: Samstag 28. Dezember 2019, 11:28 Bitte zeige deinen Code, was passiert und was du stattdessen erwartest.
Du rufst doch auch nicht in einer Werkstatt an, sagst dass du seit einer Woche Auto fährst und heute morgen nichts passiert, als du den Schlüssel ins Zündschloss gesteckt hast, um dann zu fragen, ob die mal ein ähnliches Problem hatten.
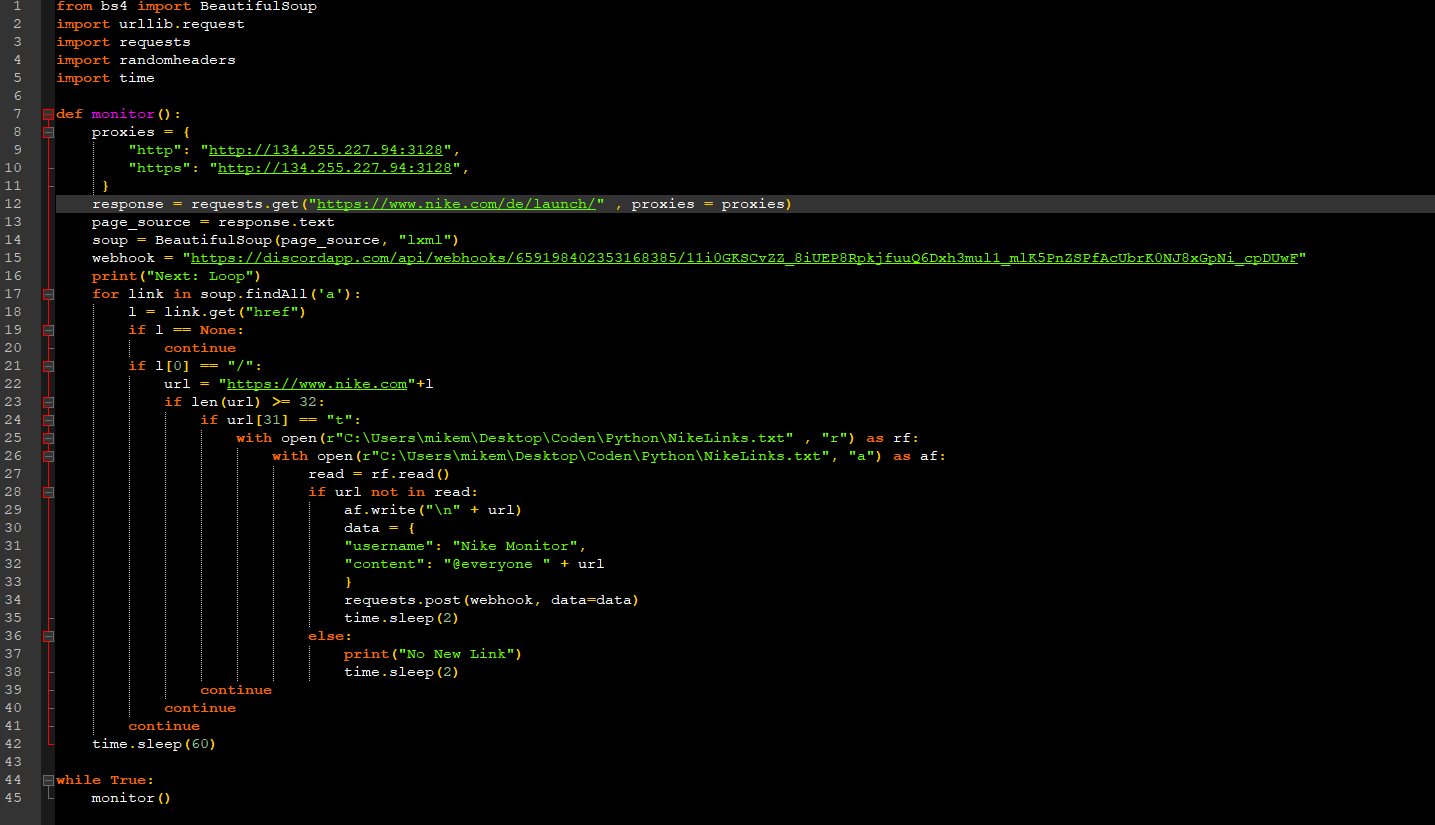
Hier klappts nicht
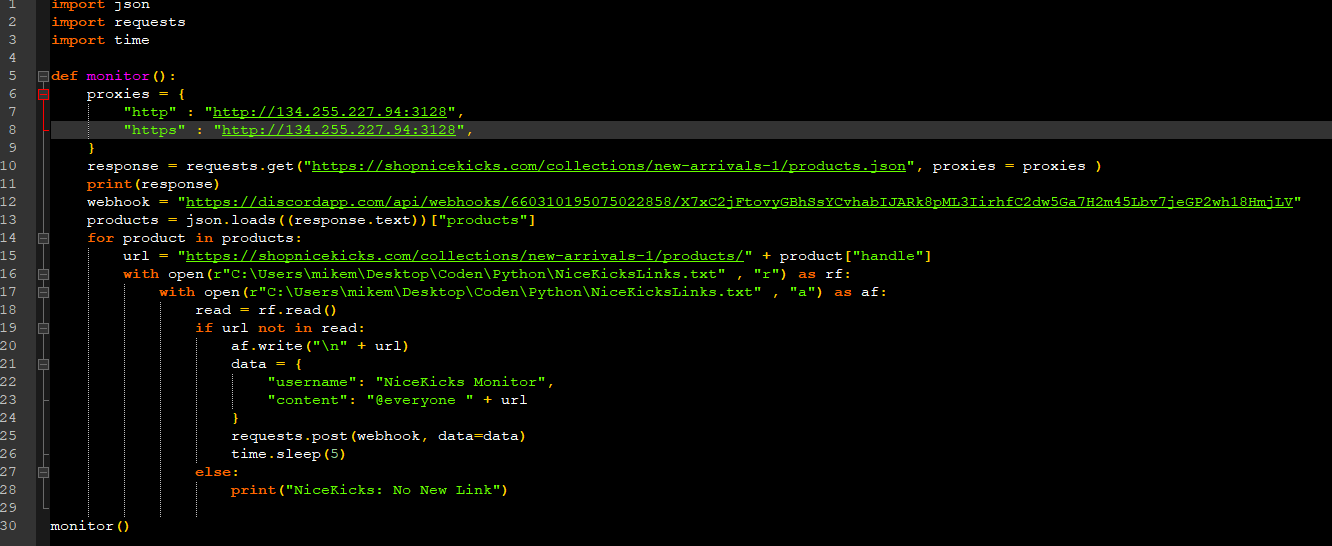
Mir geht es nur um den request warum ich dort keine Antwort bekomme.
Danke für die schnelle Antwort
-
panikgurke
- User
- Beiträge: 3
- Registriert: Samstag 28. Dezember 2019, 02:00
-
__blackjack__

- User
- Beiträge: 14418
- Registriert: Samstag 2. Juni 2018, 10:21
- Wohnort: 127.0.0.1
- Kontaktdaten:
@panikgurke: Anmerkungen zum Code der klappt:
`urllib.request` und `randomheaders` werden importiert aber nicht verwendet.
Daten wie die Proxies, die URLs, und Dateinamen würde man als Konstanten definieren um sie einfacher ändern zu können und teilweise Duplikate zu vermeiden.
Bei den Antworten auf `requests`-Aufrufe sollte man prüfen ob da tatsächlich der Inhalt zurück kommt oder eine Fehlermeldung vom Server.
`bs4` hat mittlerweile Methodennamen die den Python-Konventionen entsprechen. Die alten Namen sollten man nicht mehr verwenden. Also `find_all()` anstelle von `findAll()`. Wobei man in dem Fall von dieser Methode auch einfach das `soup`-Objekt aufrufen kann.
Man kann auch gleich beim Suchen nur nach solchen <a>-Elementen suchen die ein `href`-Attribut haben. Damit wird man dann schon mal das erste ``continue`` los. ``continue`` ist eine Anweisung die man meiden sollte wo es geht, und es geht fast immer. Das ist ein unbedingter Sprung den man nicht an der Codestruktur sehen kann und die Anweisung macht es schwerer Code aus Schleifen in Funktionen heraus zu ziehen.
`l` ist kein guter Name, weil er nicht beschreibt was der Wert bedeutet. `url` wäre beispielsweise besser geeignet.
Der Code kann nicht damit umgehen wenn das `href`-Attribut eine leere Zeichenkette enthält. Statt auf das erste Element zuzugreifen und das mit "/" zu vergleichen sollte man die `startswith()`-Methode verwenden die auch mit leeren Zeichenketten klar kommt:
Wobei man auch diesen Test gleich mit in die Suche integrieren könnte, denn man kann da auch kompilierte reguläre Ausdrücke oder Funktionen die den Inhalt testen übergeben.
Wenn sich die Länge der Basisurl mal ändern sollte dann müssen auch die magischen Zahlen 32 und 31 geändert werden. Es wäre besser wenn diese Werte unabhängig von der Basisurl für "nike.com" wären, man also die erst nach den Tests vor den URL-Teil aus der Webseite stellt. Dann hat man auch drei direk ineinander verschachtelte ``if``\s die man zu *einem* ``if`` mit diesen Bedingungen zusammenfassen kann.
`rf` und `af` sind wieder schlechte Namen. Wenn man das erstellen der beiden Dateiobjekte nicht unsinnigerweise verschachteln würde, könnte man da in beiden Fällen einfach `urls_file` für verwenden.
`read` ist auch kein guter Name weil er dem Leser nicht verrät was der Wert enthält. Das die Daten ”gelesen” wurden ist nach dem einlesen ja nicht so interessant wie die Information was die gelesenen Daten denn bedeuten.
Auch wenn URLs syntaktisch gesehen keine URLs enthalten können ohne das bestimmte Zeichen davon escaped werden und damit der ``in``-Test in die gelesenen Daten immer funktionieren müsste sofern das HTML keine ungültigen URL(-Teile) enthält, wäre es sauberer die Datei in eine Liste einzulesen. Oder noch besser ein `set()` damit beim Test dann nicht linear über die Daten gegangen werden muss.
Das Zeilenende-Zeichen "\n" gehört ans Ende einer jeden Zeile. Du erzeugst da Dateien bei denen die letzte Zeile nicht auf diese weise abgeschlossen ist, was Probleme verursachen kann die man sich ersparen sollte.
Bei Textdateien sollte man immer eine explizite Kodierung angeben. Bei einer Datei die URLs enthält kann das ASCII sein, weil URLs nichts ausser ASCII enthalten dürfen. Gegen eine eventuelle Ausnahme möchte man den Schreibvorgang in die Datei eventuell absichern. Oder man testet das schon selbst bevor man anfängt Dateien zum lesen oder schreiben zu öffnen.
Zwischenstand (ungetestet):
Die `monitor()`-Funktion macht ganz schön viel, da könnte man Teilaufgaben in eingene Funktionen heraus ziehen.
Nun zum nicht funktioniernden Code. So einiges zum ersten Programm gilt auch hier.
Man braucht das `json()`-Modul nicht, denn `Response`-Objekte von `requests` haben eine `json()`-Methode.
Zwischenstand (ungetestet):
Hier sieht man dann noch einen guten Grund `monitor()` in mehrere Funktionen zu zerlegen: Die beiden Programme sind *sehr* ähnlich aufgebaut und man kann da einiges heraus ziehen was man in ein eigenes Modul stecken kann, welches von beiden Programmen verwendet werden kann.
Zu dem ”klappt nicht” müsstest Du mal verraten was das genau bedeutet. Gibt es eine Fehlermeldung? Falls ja, wie lautet die? Komplett mit Traceback 1:1 kopiert bitte. Falls es sich nicht so verhält wie Du erwartest — was erwartest Du denn? Und was passiert stattdessen?
`urllib.request` und `randomheaders` werden importiert aber nicht verwendet.
Daten wie die Proxies, die URLs, und Dateinamen würde man als Konstanten definieren um sie einfacher ändern zu können und teilweise Duplikate zu vermeiden.
Bei den Antworten auf `requests`-Aufrufe sollte man prüfen ob da tatsächlich der Inhalt zurück kommt oder eine Fehlermeldung vom Server.
`bs4` hat mittlerweile Methodennamen die den Python-Konventionen entsprechen. Die alten Namen sollten man nicht mehr verwenden. Also `find_all()` anstelle von `findAll()`. Wobei man in dem Fall von dieser Methode auch einfach das `soup`-Objekt aufrufen kann.
Man kann auch gleich beim Suchen nur nach solchen <a>-Elementen suchen die ein `href`-Attribut haben. Damit wird man dann schon mal das erste ``continue`` los. ``continue`` ist eine Anweisung die man meiden sollte wo es geht, und es geht fast immer. Das ist ein unbedingter Sprung den man nicht an der Codestruktur sehen kann und die Anweisung macht es schwerer Code aus Schleifen in Funktionen heraus zu ziehen.
`l` ist kein guter Name, weil er nicht beschreibt was der Wert bedeutet. `url` wäre beispielsweise besser geeignet.
Der Code kann nicht damit umgehen wenn das `href`-Attribut eine leere Zeichenkette enthält. Statt auf das erste Element zuzugreifen und das mit "/" zu vergleichen sollte man die `startswith()`-Methode verwenden die auch mit leeren Zeichenketten klar kommt:
Code: Alles auswählen
In [17]: l = ""
In [18]: l[0] == "/"
---------------------------------------------------------------------------
IndexError Traceback (most recent call last)
<ipython-input-18-804750105825> in <module>
----> 1 l[0] == "/"
IndexError: string index out of range
In [19]: l.startswith("/")
Out[19]: FalseWenn sich die Länge der Basisurl mal ändern sollte dann müssen auch die magischen Zahlen 32 und 31 geändert werden. Es wäre besser wenn diese Werte unabhängig von der Basisurl für "nike.com" wären, man also die erst nach den Tests vor den URL-Teil aus der Webseite stellt. Dann hat man auch drei direk ineinander verschachtelte ``if``\s die man zu *einem* ``if`` mit diesen Bedingungen zusammenfassen kann.
`rf` und `af` sind wieder schlechte Namen. Wenn man das erstellen der beiden Dateiobjekte nicht unsinnigerweise verschachteln würde, könnte man da in beiden Fällen einfach `urls_file` für verwenden.
`read` ist auch kein guter Name weil er dem Leser nicht verrät was der Wert enthält. Das die Daten ”gelesen” wurden ist nach dem einlesen ja nicht so interessant wie die Information was die gelesenen Daten denn bedeuten.
Auch wenn URLs syntaktisch gesehen keine URLs enthalten können ohne das bestimmte Zeichen davon escaped werden und damit der ``in``-Test in die gelesenen Daten immer funktionieren müsste sofern das HTML keine ungültigen URL(-Teile) enthält, wäre es sauberer die Datei in eine Liste einzulesen. Oder noch besser ein `set()` damit beim Test dann nicht linear über die Daten gegangen werden muss.
Das Zeilenende-Zeichen "\n" gehört ans Ende einer jeden Zeile. Du erzeugst da Dateien bei denen die letzte Zeile nicht auf diese weise abgeschlossen ist, was Probleme verursachen kann die man sich ersparen sollte.
Bei Textdateien sollte man immer eine explizite Kodierung angeben. Bei einer Datei die URLs enthält kann das ASCII sein, weil URLs nichts ausser ASCII enthalten dürfen. Gegen eine eventuelle Ausnahme möchte man den Schreibvorgang in die Datei eventuell absichern. Oder man testet das schon selbst bevor man anfängt Dateien zum lesen oder schreiben zu öffnen.
Zwischenstand (ungetestet):
Code: Alles auswählen
#!/usr/bin/env python3
import time
import requests
from bs4 import BeautifulSoup
NIKE_BASE_URL = "https://www.nike.com"
URLS_FILENAME = r"C:\Users\mikem\Desktop\Coden\Python\NikeLinks.txt"
DISCORD_USERNAME = "Nike Monitor"
DISCORD_WEBHOOK_URL = (
"https://discordapp.com/api/webhooks/659198402353168385/"
"11i0GKSCvZZ_8iUEP8RpkjfuuQ6Dxh3mul1_mlK5PnZSPfAcUbrK0NJ8xGpNi_cpDUwF"
)
PROXIES = {
"http": "http://134.255.227.94:3128",
"https": "http://134.255.227.94:3128",
}
def monitor():
response = requests.get(f"{NIKE_BASE_URL}/de/launch/", proxies=PROXIES)
response.raise_for_status()
soup = BeautifulSoup(response.text, "lxml")
for url in (node["href"] for node in soup("a", href=True)):
#
# TODO Integrate this test into the `soup` call, either as compiled
# regular expression or as function/``lambda`` expression.
#
if url.startswith("/") and len(url) >= 12 and url[11] == "t":
url_line = f"{NIKE_BASE_URL}{url}\n"
with open(URLS_FILENAME, "r", encoding="ascii") as urls_file:
url_lines = set(urls_file)
with open(URLS_FILENAME, "a", encoding="ascii") as urls_file:
if url_line not in url_lines:
#
# TODO It would be more efficient to test for ASCII'ness
# before opening any file.
#
try:
urls_file.write(url_line)
except UnicodeEncodeError:
print(f"URL line not ASCII: {url_line!a}")
else:
requests.post(
DISCORD_WEBHOOK_URL,
data={
"username": DISCORD_USERNAME,
"content": f"@everyone {url_line.rstrip()}",
},
).raise_for_status()
time.sleep(2)
else:
print("Not a new URL:", url_line, end="")
time.sleep(60)
def main():
while True:
monitor()
if __name__ == "__main__":
main()Nun zum nicht funktioniernden Code. So einiges zum ersten Programm gilt auch hier.
Man braucht das `json()`-Modul nicht, denn `Response`-Objekte von `requests` haben eine `json()`-Methode.
Zwischenstand (ungetestet):
Code: Alles auswählen
#!/usr/bin/env python3
import time
import requests
NICEKICKS_BASE_URL = "https://shopnicekicks.com/collections/new-arrivals-1/"
URLS_FILENAME = r"C:\Users\mikem\Desktop\Coden\Python\NiceKicksLinks.txt"
DISCORD_USERNAME = "NiceKicks Monitor"
DISCORD_WEBHOOK_URL = (
"https://discordapp.com/api/webhooks/660310195075022858/"
"X7xC2jFtovyGBhSsYCvhabIJARk8pML3IirhfC2dw5Ga7H2m45Lbv7jeGP2wh18HmjLV"
)
PROXIES = {
"http": "http://134.255.227.94:3128",
"https": "http://134.255.227.94:3128",
}
def monitor():
response = requests.get(
f"{NICEKICKS_BASE_URL}products.json", proxies=PROXIES
)
response.raise_for_status()
for product in response.json()["products"]:
url_line = f"{NICEKICKS_BASE_URL}products/{product['handle']}\n"
with open(URLS_FILENAME, "r", encoding="ascii") as urls_file:
url_lines = set(urls_file)
with open(URLS_FILENAME, "a", encoding="ascii") as urls_file:
if url_line not in url_lines:
#
# TODO It would be more efficient to test for ASCII'ness
# before opening any file.
#
try:
urls_file.write(url_line)
except UnicodeEncodeError:
print(f"URL line not ASCII: {url_line!a}")
else:
data = {
"username": DISCORD_USERNAME,
"content": f"@everyone {url_line.rstrip()}",
}
requests.post(
DISCORD_WEBHOOK_URL, data=data
).raise_for_status()
time.sleep(5)
else:
print("Not a new URL:", url_line, end="")
def main():
monitor()
if __name__ == "__main__":
main()Zu dem ”klappt nicht” müsstest Du mal verraten was das genau bedeutet. Gibt es eine Fehlermeldung? Falls ja, wie lautet die? Komplett mit Traceback 1:1 kopiert bitte. Falls es sich nicht so verhält wie Du erwartest — was erwartest Du denn? Und was passiert stattdessen?
“The city's central computer told you? R2D2, you know better than to trust a strange computer!” — C3PO