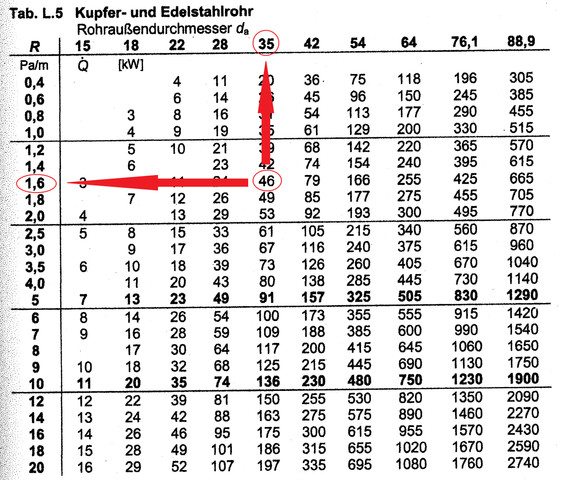
Ein Freund von mir und ich haben zusammen den Nachfolgenden Code zur Durchsuchung eines CSV Datei geschrieben. Da die Durchsuchung Spaltenweise erfolgen soll und die Ausgabe soll der Wert in der
Kopfzeile sein und der am Anfang von der Zeile. Auf dem Bild seht ihr die Orginall Tabelle. Die Kopfzeile ist die Zeile 0 und die Erste Spalte ist die Spalte 0. Der Code Funktioniert auch so wie er soll. Ich würde gerne
wissen ob jemand Verbesserungsvorschläge hat, da er mit zu 'Klobig' vorkommt. Eine Umstellung der Tabelle würde ich gerne vermeiden um Fehler vor zu beugen die da durch entstehen können das auch jemand anderes die Tabelle überprüfen kann, ohne das er Umdenken muss.
Code: Alles auswählen
import csv
inputfile="KupferUndEdelstahlrohr.csv"
#in dieser Datei müssen in jeder Zelle Zahlen
#stehen, bei denen nachkommas mit "." getrennt sind
#Initialize
search=input('Wie groß ist die Leistung des Gerätes? ')
searchfound=False
dataset=[]
row=[]
rowcnt=0
colcnt=0
colmax=0
with open(inputfile, newline='') as csvfile:
table = csv.reader(csvfile, delimiter=';', quotechar='"')
for rows in table:
for col in rows:
row.append(col)
colcnt=len(rows)
if colcnt > colmax:
colmax = colcnt
colcnt =0
rowcnt +=1
dataset.append(rows)
#Array from csv is now saved in dataset
#print(list(range(colmax)))
#print(list(range(rowcnt)))
for outer in list(range(colmax)):
if searchfound==False:
for inner in list(range(rowcnt)):
#print(dataset[inner][outer])
if dataset[inner][outer] == "xx":
continue
elif (float(dataset[inner][outer]) >= float(search)) and (outer and inner):
print()
#print("Die eingegebene Leistung wurden an folgender Position gefunden")
#print()
#print("Zeile: " + str(inner) +" /"+" Spalte: " + str(outer))
#print()
print('Die nächstgelegene Leistung beträgt: ' + str(dataset[inner][outer]) + ' kW')
print("Der Druckverlust beträgt " + dataset[inner][0] + " mbar/m2")
print("Der rohrdurchmesser beträgt " + dataset[0][outer]+ " mm")
print()
searchfound=True
break