Ich habe eine kurze Frage zu einer Code Zeile diese habe Ich aus einem Forum und macht auch genau das was Sie soll nur Ich verstehe leider nicht ganz wie Sie das macht und würde das gerne einmal erklärt haben:
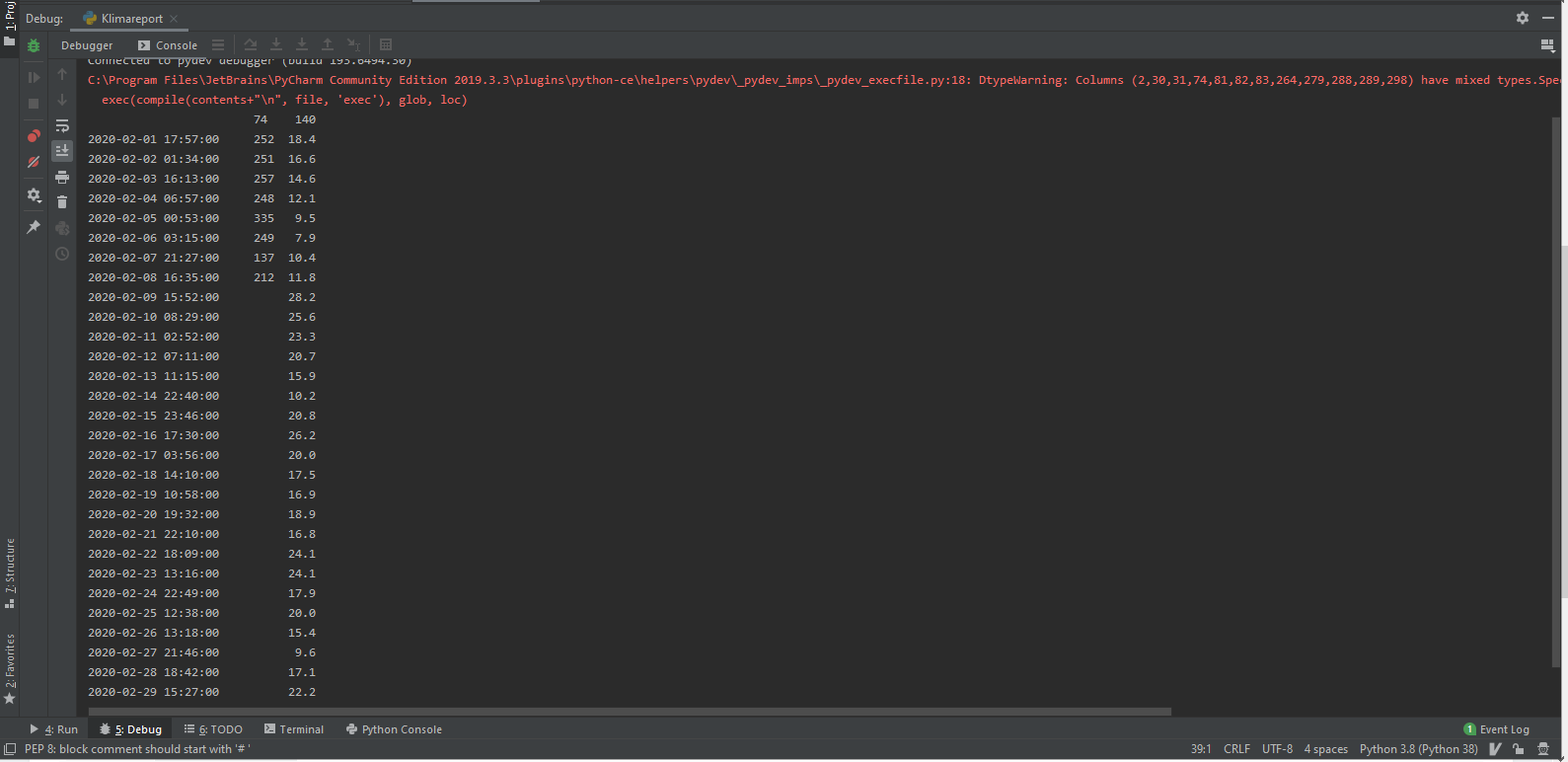
Ich habe folgenden Dataframe: ( Die Beschriftungen 74 ,140 sind Kanalnummern und es ist normal das bei 74 Daten nicht vorhanden sind ( da es dort keine Messdaten gegeben hat )
daten_intervalle:
So nun wollte Ich gerne folgendes haben Ich habe ein bestimmten Intervall ( 1 Tag ) und Ich wollte das in diesem Tag der höchste Wert von 140 genommen wird und mir dann mit dem wert angezeigt wird von 74 :
Die Zeile die Ich aus dem Forum habe ist folgende:
daten_mit_intervallen.loc [daten_mit_intervallen.groupby( pd.Grouper( freq = 'D' ) ).idxmax().iloc [:, 0]]
Das Ergebnis sieht dann wie folgt aus:
Zusammengefasst:
Er nimmt die Rechte Spalte und sortiert diese nach dem Max Wert des Angegebenen Intervalls:
Fragen:
Wie macht er das Ich übergebe Ihn so ja den kompletten Datenframe woher weiß es das Ich die Rechte Spalte nach dem Maxwert Sortiert haben möchte und die anderen Werte sollen
dann so angegebenen werden wie Sie sind und nicht auch nach ihren Maxwerten sortiert werden?
Und wieso muss Ich iloc[:,0] am Ende nehmen
Versuchte Erklärungen:
Wenn Ich iloc[:0] mir vor der Bearbeitung anzeigen lass kommt nur die Spalte 74 ( was Ich verstehe) ist jetzt zu null geworden da Ich Pandas keine explizieten Spalten genannt habe die er gruppieren soll ( nimmt er dann alle) was bedeutet würde Ich hätte nur noch 1 Spalte -> was die 0te Stelle wäre? Das macht nur kein Sinn weil wenn ICh mir in Pycharm den Datenframe angucke steht bei beiden Datenframes (41760 = länge,2=Spalten),(29,2) das die länge weniger wird ist ja selbstverständlich.
Und die die default Einstellung von id.max() ist Reihenweise das verstehe Ich auch nur Ich Verstehe dort nicht wieso er das trotzdem dann nicht auch für Splate 74 macht.
Ich danke euch


{kind=link}