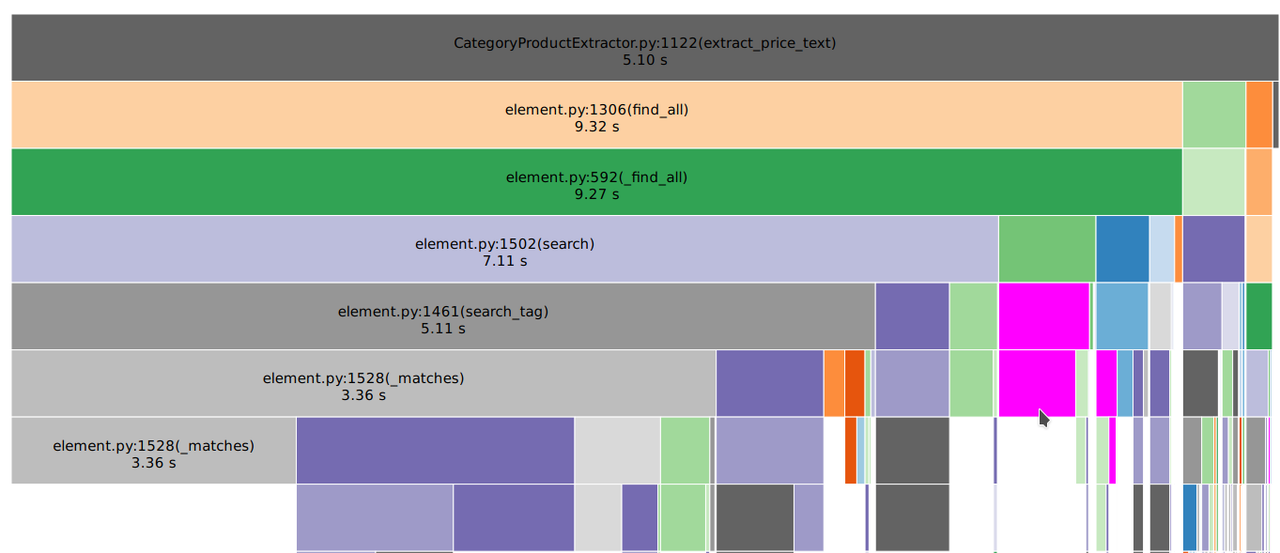
ich habe ein Programm, welches aus HTML Dateien Strings extrahieren soll.
Dazu verwende ich BeautifulSoup4 in Kombination mit tonnenweise for, if, try etc.
Code: Alles auswählen
def extract_description(self, html):
soup = BeautifulSoup(str(html), 'lxml')
descr = soup.find_all('p', itemprop='description')
if len ( descr ) == 1:
return ( descr[0].getText().strip() )
descr = soup.find_all('div', class_='product--description')
if len ( descr ) == 1:
return ( descr[0].getText().strip() )
for input in soup.find_all('input', type='hidden'):
if input.name == 'description':
return (input['value'])
return (None)
Gibt es eine Liste mit Prinzipien oder generell Tips wie ich hier die CPU entlasten kann?
Evtl. auch einen Hinweis, wie ich den Code insgesamt verbessern/optimieren kann.
Bisher habe ich die Optionen die möglichst häufig vorkommen in den HTML Dateien versucht weit nach oben in die Methoden zu packen.
Zusätzlich habe ich bei den for loops geschaut, ob ich welche zusammenfassen kann und dann innerhalb der loops mit mehreren ifs testen.
Und zusätzlich verwende ich bei den neuen Methoden das soup Objekt als Klassenvariable, anstelle einen HTML string per Parameter zu übergeben und soup wieder zu instanzieren.
Habt ihr Vorschläge?