Anfängerfrage zu .split Funktion auf gewöhnlichen Text
Verfasst: Samstag 15. Mai 2021, 17:56
Hey ich habe ein Problem und raff es einfach nicht fürchte ich:
Hier zunächst mal ein bild wie es in der Konsole auschaut:
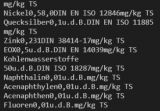
Ich möchte lediglich von diesem Text, der einer .pdf extrahiert wurde, einen Textschnipsel extrahieren. Bisher hat das auch ganz wunderbar geklappt, z.B.:
So konnte ich viele Dinge extrahieren. Doch wenn ich das Folgende versuche, gehts auf einmal nicht mehr, er hat Probleme zwischen naphtalin und 0,01 - vllt. eiN Zeichen, welches ich nicht sehe o.a.? :
Fehler:
IndexError: list index out of range,
naph_A_raw = pageObj_A.split('Naphtalin0,01')[1]
Aber wieso denn ? Das is doch einfach nur zusammengeklitschter Text, den ich versuiche ganz stumpf von einander zu trennen Hat jemand nen Rat?
Hat jemand nen Rat?
Hier zunächst mal ein bild wie es in der Konsole auschaut:
Ich möchte lediglich von diesem Text, der einer .pdf extrahiert wurde, einen Textschnipsel extrahieren. Bisher hat das auch ganz wunderbar geklappt, z.B.:
Code: Alles auswählen
quecksilber_A_raw = pageObj_A.split('Quecksilber0,1')[1]
quecksilber_A_raw = quecksilber_A_raw.split('DIN EN ISO 11885')[0]Code: Alles auswählen
naph_A_raw = pageObj_A.split('Naphtalin0,01')[1]
naph_A_raw = naph_A_raw.split('DIN EN ISO 11885')[0]IndexError: list index out of range,
naph_A_raw = pageObj_A.split('Naphtalin0,01')[1]
Aber wieso denn ? Das is doch einfach nur zusammengeklitschter Text, den ich versuiche ganz stumpf von einander zu trennen

