Danke. Das bestärkt mich in meiner Meinung, dass 1 Datei genügen muss. eine aufs Arbeitsverzeichnis und 1 auf den Stick zurück.
Aber ich glaube, außer der Tatsache, dass der Stick gezogen wird, werden die anderen Fälle nicht eintreten. Das Arbeitsverzeichnis liegt ja im Home vom User. sollte also keine Berechtigungsprobleme geben. Und wenn der
Stick ausgeworfen wird, passiert halt mal nichts solange bis die richtigen Datein da sind. (ich weiß, was du meinst. Hab grade beim Fehlerabfangen getestet und ein Stick hat immer nur 3 Dateien geschafft, bei der 4 hat er den Stick ausgeworfen. Der andere Stick hat das problemlos gemacht. Auf beiden waren die Dateien da)
Das mit der DB hatte ich verworfen, weil ich annehme, dass die am einfachsten von Access eine csv-Datei auf den Raspi bringen können. Mittlerweile bin ich da auch wieder nicht mehr so sicher. Könnte auch xml sein.
Vielleicht bastle ich auch noch ein Excel-Makro, das mir die Datei aus der DB so ausliest wie ich sie brauche.
Bisher hab ich den Aufwand gescheut, weil wie gesagt, ist für den weiteren Ablauf des Druckprogramms genau 1 Datei wichtig. Die zweite ist ja dafür die Anzahl zu protokollieren.
Mal sehen.
Wahrscheinlich lande ich doch bei der DB.
Labeldruck und was draus folgt
-
__blackjack__

- User
- Beiträge: 13116
- Registriert: Samstag 2. Juni 2018, 10:21
- Wohnort: 127.0.0.1
- Kontaktdaten:
@theoS: Noch mal, vergiss das irgendwelche Fehler nicht auftreten könnten. Das ist alles irrelevant wenn Du nicht vorher versuchst auf alles möglich zu prüfen oder eben auch Prüfungen weg lässt, wenn Du einfach alles *machst* aber eben nicht direkt die Datei(en) überschreibst.
Berechtigungsprobleme kann es beispielsweise geben wenn bei dem Datenträger Schreib- oder Leseprobleme auftreten und deswegen das Dateisystem auf „read only“ gestellt wird.
Auf dem Zielrechner eine DB zu verwenden sagt ja nichts darüber in welchem Format die Daten auf dem Stick liegen. Dort kann ja weiterhin eine CSV-Datei vorliegen und auch der alte Zustand kann als CSV-Datei dort geschrieben werden.
Berechtigungsprobleme kann es beispielsweise geben wenn bei dem Datenträger Schreib- oder Leseprobleme auftreten und deswegen das Dateisystem auf „read only“ gestellt wird.
Auf dem Zielrechner eine DB zu verwenden sagt ja nichts darüber in welchem Format die Daten auf dem Stick liegen. Dort kann ja weiterhin eine CSV-Datei vorliegen und auch der alte Zustand kann als CSV-Datei dort geschrieben werden.
„All religions are the same: religion is basically guilt, with different holidays.” — Cathy Ladman
@__blackjack__
Klar kann man immer irgendwas finden, dass das Programm nicht mehr geht. Aber ich will das Zeug eher einfach haben. Wenn die das schaffen, das Dateisystem nur noch readonly zu setzen ohne ein Bedienelement, dann bekommen die neben meinem Respekt einfach eine neue SD-Karte zugeschickt.
Dahingehend ist mir für solche Fälle auch nicht klar was da abzufangen wäre. Und eine DB würde dadran auch nichts ändern. Die muss auch beschrieben werden.
Ich hab gestern noch eine Idee gehabt, das Überprüfen an einer anderen Stelle zu machen, wenn das so klappt wie gedacht, dann solls gut sein.
Aber noch was anderes.
Was hältst du von der Idee, den Namen des Sticks der ja in jeder der Funktionen gebraucht wird als globale Variable zu verwenden?
Dann muss man das nicht immer jedesmal übergeben.
Klar kann man immer irgendwas finden, dass das Programm nicht mehr geht. Aber ich will das Zeug eher einfach haben. Wenn die das schaffen, das Dateisystem nur noch readonly zu setzen ohne ein Bedienelement, dann bekommen die neben meinem Respekt einfach eine neue SD-Karte zugeschickt.
Dahingehend ist mir für solche Fälle auch nicht klar was da abzufangen wäre. Und eine DB würde dadran auch nichts ändern. Die muss auch beschrieben werden.
Ich hab gestern noch eine Idee gehabt, das Überprüfen an einer anderen Stelle zu machen, wenn das so klappt wie gedacht, dann solls gut sein.
Aber noch was anderes.
Was hältst du von der Idee, den Namen des Sticks der ja in jeder der Funktionen gebraucht wird als globale Variable zu verwenden?
Dann muss man das nicht immer jedesmal übergeben.
-
__blackjack__
- User
- Beiträge: 13116
- Registriert: Samstag 2. Juni 2018, 10:21
- Wohnort: 127.0.0.1
- Kontaktdaten:
@theoS: Vorher nur einen Teil der Bedingung zu testen bevor man etwas macht ist doch aber gerade *nicht* einfacher, als es einfach zu machen, in einer Art die das Problem umgeht und auf Ausnahmen die dabei entstehen können zu reagieren. Der Test ob beide Dateien vorhanden sind kommt doch wenn man sie einfach kopiert frei Haus. Sind sie es nicht gibt es mindestens einen `FileNotFoundError`. Auf den sollte man so oder so angemessen reagieren, auch wenn man vorher die Existenz geprüft hat.
Das mit dem „readonly“ ist ganz einfach, da braucht kein Benutzer was für tun: Wenn das System Inkonsistenzen beim Dateisystem feststellt, zum Beispiel weil das Speichermedium defekt ist, dann schaltet das normalerweise automatisch auf „readonly“ um, damit man mit weiteren Schreibzugriffen das Dateisystem nicht noch mehr kaputt machen kann. Gerade bei SD-Karten soll das öfter passieren als bei Festplatten.
Eine transaktionsfähige Datenbank ändert in sofern etwas als dass man deutlich einfacher wirklich sicherstellen kann, dass man entweder eine komplette Aktualisierung bekommt, oder gar keine. Egal was zwischendurch schief läuft. Genau für so etwas sind Transaktionen ja da.
Von globalen Variablen halte ich überhaupt nichts. Wo ist das Problem den Wert als Argument zu übergeben?
Das mit dem „readonly“ ist ganz einfach, da braucht kein Benutzer was für tun: Wenn das System Inkonsistenzen beim Dateisystem feststellt, zum Beispiel weil das Speichermedium defekt ist, dann schaltet das normalerweise automatisch auf „readonly“ um, damit man mit weiteren Schreibzugriffen das Dateisystem nicht noch mehr kaputt machen kann. Gerade bei SD-Karten soll das öfter passieren als bei Festplatten.
Eine transaktionsfähige Datenbank ändert in sofern etwas als dass man deutlich einfacher wirklich sicherstellen kann, dass man entweder eine komplette Aktualisierung bekommt, oder gar keine. Egal was zwischendurch schief läuft. Genau für so etwas sind Transaktionen ja da.
Von globalen Variablen halte ich überhaupt nichts. Wo ist das Problem den Wert als Argument zu übergeben?
„All religions are the same: religion is basically guilt, with different holidays.” — Cathy Ladman
Naja, das übt. Aber sonst ist das eigentlich ein Klassiker für mich, wo man so was gebrauchen kann. Der Name muss einmal bestimmt werden und steht dann überall zur Verfügung. So muss ich bei der einen Funktion 3 Parameter übergeben. Dabei passiert mir das schon mal, dass ich die Reihenfolge vertausche. Mich verwirren Parameter.Von globalen Variablen halte ich überhaupt nichts. Wo ist das Problem den Wert als Argument zu übergeben?
Aber ich hab mir das schon fast gedacht. Ist wahrscheinlich auch so was wie Philosophie.
Das verstehe ich immer noch nicht.Eine transaktionsfähige Datenbank ändert in sofern etwas als dass man deutlich einfacher wirklich sicherstellen kann, dass man entweder eine komplette Aktualisierung bekommt, oder gar keine
Wenn die Datei nicht da ist, die drauf soll, ist es doch piepegal, ob der »Empfänger« eine Datenbank ist oder eine Datei die geschrieben wird.
Wenn auch nur 1 davon geschrieben wird, bleibt ja immer noch die Zweite, die ist ja dann auch nicht auf der Datenbank.
Verstehen würde ich das, wenn das Ding online irgendwo am Netz hinge, aber so? (ich mein, erzeugt hab ich schon mal testweise eine, aber weiter hab ich dann nicht gemacht, weil das dann noch einen Zwischenschritt erfordert: Von Access zu CSV von CSV zu sqlite und dann sqlite von zu dem ZPL-Druckcode)
Vielleicht fehlt mir da noch das tiefere Verständnis, momentan kapiere ich keine Vorteile.
Bin aber gerne bereit, hier dazuzulernen.
Das stimmt schon, aber ich habe beim besten Willen keine Möglichkeit gefunden darauf so zu reagieren, dass der Code weiterläuft. (womit ich die Überwachung des USB-Ports nach anstecken meine)Der Test ob beide Dateien vorhanden sind kommt doch wenn man sie einfach kopiert frei Haus
Bei all den Versuchen hat mich die Ausnahme rausgeworfen.
Jetzt hab ich mir nicht mehr anders zu helfen gewusst, als schon beim Anstecken zu prüfen: Sind die Dateien überhaupt beide da? Wenn nein--> Raus mit dem Stick.
Wenn dann noch eine Exception auftaucht: Raus mit dem Stick.
So hab ich - für mein Verständnis - verhindert, dass überhaupt was passiert wenn eine der Dateien fehlt. Was immer noch passieren kann ist das, dass eine Datei draufgespielt wurde, die andere nicht.
Code: Alles auswählen
from pathlib import Path
import pyudev
import time
#import pathlib
from datetime import datetime as DateTime
import subprocess
PFAD = Path.home() / ".DruckData"
###----wird später gebraucht------
##ABFRAGE_FILENAME = PFAD / "TB_Ausgabe_Abfrage8StueckII.txt"
##ZAEHLER_FILENAME = PFAD / "numbers.csv"
###------------------------------
MEDIA_PFAD = Path('/media/earl/')
WECHSEL_DATEI_NAMEN = ["numbers.csv", "TB_Ausgabe_8iii.txt"]
print(MEDIA_PFAD)
def usb_ansteckerkenner(context):
monitor = pyudev.Monitor.from_netlink(context)
monitor.filter_by('block')
for device in iter(monitor.poll, None):
if 'ID_FS_TYPE' in device: ###
print(device.action)
if device.action == 'add':
name_of_stick = Path(device.get('ID_FS_LABEL'))
time.sleep(2)
gehts_weiter = pruef_ob_da(name_of_stick)
if gehts_weiter == 1:
return name_of_stick
else:
rauswerfer(name_of_stick)
def copy(name_of_stick, source_path, destination_path ):
try:
text = source_path.read_text(encoding="utf-8")
destination_path.write_text(text, encoding="utf-8")
except FileNotFoundError as error:
print(error)
def pruef_ob_da(name_of_stick):
x=0
for dateiname in map(Path, WECHSEL_DATEI_NAMEN):
if (MEDIA_PFAD / name_of_stick / dateiname).is_file():
x=x+1
if x == 2:
return 1
else:
print("nope")
def rauswerfer(name_of_stick):
#print(name_of_stick, "wird rausgeworfen")
umount_result = subprocess.run(["umount", MEDIA_PFAD / name_of_stick], check=True, stdout=subprocess.PIPE)
#print(umount_result.stdout, "Ergebnis von Umount")
def datei_auf_stick(name_of_stick, dateipfad, timestamp):
copy(name_of_stick,
PFAD / dateipfad,
MEDIA_PFAD
/ name_of_stick
/ dateipfad.with_name(
f"{dateipfad.stem}_{timestamp:%Y-%m-%d_%H_%M}.csv"
),
)
def datei_auf_arbeitsverzeichnis(name_of_stick, dateipfad):
copy(name_of_stick, MEDIA_PFAD / name_of_stick / dateipfad, PFAD / dateipfad)
def main():
context = pyudev.Context()
while True:
timestamp = DateTime.now()
name_of_stick = usb_ansteckerkenner(context)
for dateiname in map(Path, WECHSEL_DATEI_NAMEN):
try:
datei_auf_stick(name_of_stick, dateiname, timestamp)
datei_auf_arbeitsverzeichnis(name_of_stick, dateiname)
except:
rauswerfer(name_of_stick)
if __name__ == "__main__":
main()
-
__blackjack__
- User
- Beiträge: 13116
- Registriert: Samstag 2. Juni 2018, 10:21
- Wohnort: 127.0.0.1
- Kontaktdaten:
@theoS: Keine globalen Variablen ist keine Philosophie das ist „best practice“. Code mit globalem Zustand ist schwerer nachzuvollziehen, damit schwerer zu warten und zu ändern, und damit fehleranfälliger. Bei Argumenten sieht man direkt welche Werte von der Funktion verwendet werden und man kann über den Funktionsnamen in der Regel leicht alle Stellen finden von wo die Funktion mit welchen Werten aufgerufen wird. Bei globalen Variablen sind diese Zusammenhänge nicht mehr leicht nachvollziebar, denn die globale Variable kann von einer Funktion verändert werden die überhaupt nicht in der Aufrufkette liegt. Besonders lustig wird so etwas wenn die globale Variable mal nicht den Wert hat, den man da eigentlich erwartet hätte.
Man kann Funktionen auch leichter einzeln testen und wiederverwenden wenn man dafür keinen globalen Zustand berücksichtigen muss.
Verwirrend wird es auch wenn man irgendwann mal den Namen einer globalen Variable für eine lokale Variable verwendet. Sowohl beim Schreiben als auch beim Lesen muss man auf so etwas dann aufpassen.
Re Datenbank: Wenn die zweite Datei nicht da ist dann ist die erste Datei eben noch nicht in der Datenbank, denn solange die Transaktion nicht durch ein commit abgeschlossen ist, sind die Änderungen für Lesezugriffe noch nicht sichtbar und können wieder zurückgerollt werden. Das ist die Funktion von Transaktionen, dass man mehrere Änderungen machen kann, die entweder in ihrer Gesamtheit in der Datenbank landen oder gar nicht. Das auf Dateiebene selbst zu programmieren ist umständlich bis unmöglich wenn es portabel sein soll.
Du packst das auswefen des Sticks immer an komische/falsche Stellen. Die Funktion die das Anstecken des Sticks erkennen soll, sollte das Anstecken des Sticks erkennen und den Namen liefern. Und nichts anderes. Deren Aufgabe ist weder das Prüfen auf vorhandensein von Dateien noch das Auswerfen des Sticks. Das beim kopieren machen zu wollen war ja auch falsch. Das eine Funktion die `copy()` heisst und deren Aufgabe es ist *eine* Datei zu kopieren, auch den Stick auswerfen kann ist unerwartet und wie sich herausgestellt hat auch falsch, denn diese Entscheidung kann man dort überhaupt nicht treffen, weil da die nötigen Informationen fehlen. Zum Beispiel das danach vielleicht noch ein `copy()`-Aufruf kommen könnte, der ohne Stick natürlich auf die Nase fällt.
Funktionsnamen sollten die Tätigkeit beschreiben die sie durchführen. `usb_ansteckerkenner()` und `auswerfer()` sind aber keine Tätigkeiten sondern eher Namen für ”Dinge”, also eher passivere Objekte. `warten_auf_usb_stick()` und `auswerfen()` wären passender.
`timestamp` sollte nach dem warten auf den Stick ermittelt werden.
Python hat einen eigenen Datentyp für Wahrheitswerte (`bool`) mit den Werten `True` und `False`, dafür sollte man nicht die Zahlen 1 und 0 missbrauchen.
`gehts_weiter` ist überflüssig. Man muss nicht jedes Ergebnis an einen Namen binden.
Das `usb_ansteckerkenner()` nicht der geeignete Ort ist um den Stick auszuwerfen sieht man auch daran das die Funktion ja den Namen zurück gibt. Wenn Du den Stick auswirfst, dann tut sie das aber nicht, sondern gibt implizit `None` zurück, was der Code an der Aufrufstelle dann versucht als Namen für den Stick zu verwenden, was natürlich zu einer weiteren Ausnahme führen wird. Was zu einem erneuten Versuch den bereits ausgeworfenen Stick erneut auszuwerfen, was wieder zu einer Ausnahme führt. Die dann das Programm beendet. Das ist alles sehr verwirrend strukturiert.
Wobei ich gerade sehe das `copy()` im Falle einer nicht gefundenen Datei gar keine Ausnahme auslöst, der Aufrufer also gar keine Möglichkeit hat darauf zu reagieren wenn das der Fall ist. Die Ausnahmebehandlung dort ist keine sinnvolle Ausnahmebehandlung. Einen Fehler einfach ausgeben und dann so weiter machen als sei alles in Ordnung ist sehr selten ein sinnvoller Umgang mit Ausnahmen. Und wenn man eine Ausnahme nicht sinnvoll behandeln kann, sollte man sie an der Stelle einfach gar nicht behandeln.
Das implizite `None` sollte keine Funktion zurückgeben, die mindestens eine ``return``-Anweisung enthält. Falls so eine Funktion auch `None` als Rückgabewert haben kann, dann sollte das explizit mit einem ``return None`` passieren, damit der Leser das deutlich sieht, und weiss das es Absicht ist und kein Versehen weil ein Ablaufpfad in der Funktion übersehen wurde.
`pruef_ob_da()` gibt entweder 1 zurück oder auch wieder ein implizites `None`. Das sollte aber `True` und `False` sein. Im `None`-Fall wird eine Ausgabe für den Benutzer gemacht – so etwas hat in so einer Funktion nichts zu suchen.
Die hart kodierte 2 sollte da nicht stehen. Das ist die Länge der Liste mit den zu prüfenden Dateien. Wenn man die Länge ändert, an ganz anderer Stelle im Code, muss man daran denken in dieser Funktion diesen ”magischen” Wert zu ändern.
Das mit dem `x` und zählen ist auch umständlich und ineffizient. Es ist doch egal wie viele Dateien vorhanden sind, wichtig ist das alle vorhanden sind. Dazu muss man nix zählen sondern bei der ersten nicht vorhandenen Datei ist klar das nicht alle vorhanden sind. Dann steht das Ergebnis fest, auch wenn man noch nicht alle Dateien getestet hat.
Die Funktion könnte dann so aussehen:
Mit `all()` lässt sich das dann funktionaler, mit einem Ausdruck der zu `True` oder `False` ausgwertet wird, formulieren:
Ein nacktes ``except:`` ohne konkrete Ausnahmen ist selten bis nie eine gute Idee, weil es nur wenige Möglichkeiten gibt *alle* Ausnahmen, auch solche mit denen man gar nicht rechnet, sinnvoll zu behandeln. Eigentlich nur die Ausnahme zu protokollieren und dann erneut mit einem nackten ``raise`` wieder auszulösen. Letzteres kann man nur weg lassen wenn man sicher ist, dass danach kein Code mehr ausgeführt wird der zu Folgefehlern führt.
Bei Deinem Code erfolgt das Auswerfen des Sticks übrigends *nicht* wenn alle kopiert werden konnte. Soll das so? Ich hätte ja jetzt eher gedacht das es egal ist alles kopiert werden konnte oder nicht, das am Ende der Stick ausgeworfen werden soll‽
Warum bekommt `copy()` den Namen des Sticks? Der wird doch da gar nicht verwendet‽
Ungetestet:
Man kann Funktionen auch leichter einzeln testen und wiederverwenden wenn man dafür keinen globalen Zustand berücksichtigen muss.
Verwirrend wird es auch wenn man irgendwann mal den Namen einer globalen Variable für eine lokale Variable verwendet. Sowohl beim Schreiben als auch beim Lesen muss man auf so etwas dann aufpassen.
Re Datenbank: Wenn die zweite Datei nicht da ist dann ist die erste Datei eben noch nicht in der Datenbank, denn solange die Transaktion nicht durch ein commit abgeschlossen ist, sind die Änderungen für Lesezugriffe noch nicht sichtbar und können wieder zurückgerollt werden. Das ist die Funktion von Transaktionen, dass man mehrere Änderungen machen kann, die entweder in ihrer Gesamtheit in der Datenbank landen oder gar nicht. Das auf Dateiebene selbst zu programmieren ist umständlich bis unmöglich wenn es portabel sein soll.
Du packst das auswefen des Sticks immer an komische/falsche Stellen. Die Funktion die das Anstecken des Sticks erkennen soll, sollte das Anstecken des Sticks erkennen und den Namen liefern. Und nichts anderes. Deren Aufgabe ist weder das Prüfen auf vorhandensein von Dateien noch das Auswerfen des Sticks. Das beim kopieren machen zu wollen war ja auch falsch. Das eine Funktion die `copy()` heisst und deren Aufgabe es ist *eine* Datei zu kopieren, auch den Stick auswerfen kann ist unerwartet und wie sich herausgestellt hat auch falsch, denn diese Entscheidung kann man dort überhaupt nicht treffen, weil da die nötigen Informationen fehlen. Zum Beispiel das danach vielleicht noch ein `copy()`-Aufruf kommen könnte, der ohne Stick natürlich auf die Nase fällt.
Funktionsnamen sollten die Tätigkeit beschreiben die sie durchführen. `usb_ansteckerkenner()` und `auswerfer()` sind aber keine Tätigkeiten sondern eher Namen für ”Dinge”, also eher passivere Objekte. `warten_auf_usb_stick()` und `auswerfen()` wären passender.
`timestamp` sollte nach dem warten auf den Stick ermittelt werden.
Python hat einen eigenen Datentyp für Wahrheitswerte (`bool`) mit den Werten `True` und `False`, dafür sollte man nicht die Zahlen 1 und 0 missbrauchen.
`gehts_weiter` ist überflüssig. Man muss nicht jedes Ergebnis an einen Namen binden.
Das `usb_ansteckerkenner()` nicht der geeignete Ort ist um den Stick auszuwerfen sieht man auch daran das die Funktion ja den Namen zurück gibt. Wenn Du den Stick auswirfst, dann tut sie das aber nicht, sondern gibt implizit `None` zurück, was der Code an der Aufrufstelle dann versucht als Namen für den Stick zu verwenden, was natürlich zu einer weiteren Ausnahme führen wird. Was zu einem erneuten Versuch den bereits ausgeworfenen Stick erneut auszuwerfen, was wieder zu einer Ausnahme führt. Die dann das Programm beendet. Das ist alles sehr verwirrend strukturiert.
Wobei ich gerade sehe das `copy()` im Falle einer nicht gefundenen Datei gar keine Ausnahme auslöst, der Aufrufer also gar keine Möglichkeit hat darauf zu reagieren wenn das der Fall ist. Die Ausnahmebehandlung dort ist keine sinnvolle Ausnahmebehandlung. Einen Fehler einfach ausgeben und dann so weiter machen als sei alles in Ordnung ist sehr selten ein sinnvoller Umgang mit Ausnahmen. Und wenn man eine Ausnahme nicht sinnvoll behandeln kann, sollte man sie an der Stelle einfach gar nicht behandeln.
Das implizite `None` sollte keine Funktion zurückgeben, die mindestens eine ``return``-Anweisung enthält. Falls so eine Funktion auch `None` als Rückgabewert haben kann, dann sollte das explizit mit einem ``return None`` passieren, damit der Leser das deutlich sieht, und weiss das es Absicht ist und kein Versehen weil ein Ablaufpfad in der Funktion übersehen wurde.
`pruef_ob_da()` gibt entweder 1 zurück oder auch wieder ein implizites `None`. Das sollte aber `True` und `False` sein. Im `None`-Fall wird eine Ausgabe für den Benutzer gemacht – so etwas hat in so einer Funktion nichts zu suchen.
Die hart kodierte 2 sollte da nicht stehen. Das ist die Länge der Liste mit den zu prüfenden Dateien. Wenn man die Länge ändert, an ganz anderer Stelle im Code, muss man daran denken in dieser Funktion diesen ”magischen” Wert zu ändern.
Das mit dem `x` und zählen ist auch umständlich und ineffizient. Es ist doch egal wie viele Dateien vorhanden sind, wichtig ist das alle vorhanden sind. Dazu muss man nix zählen sondern bei der ersten nicht vorhandenen Datei ist klar das nicht alle vorhanden sind. Dann steht das Ergebnis fest, auch wenn man noch nicht alle Dateien getestet hat.
Die Funktion könnte dann so aussehen:
Code: Alles auswählen
def pruef_ob_da(name_of_stick):
for dateiname in map(Path, WECHSEL_DATEI_NAMEN):
if not (MEDIA_PFAD / name_of_stick / dateiname).is_file():
return False
return TrueCode: Alles auswählen
def pruef_ob_da(name_of_stick):
return all(
(MEDIA_PFAD / name_of_stick / dateiname).is_file()
for dateiname in map(Path, WECHSEL_DATEI_NAMEN)
)Bei Deinem Code erfolgt das Auswerfen des Sticks übrigends *nicht* wenn alle kopiert werden konnte. Soll das so? Ich hätte ja jetzt eher gedacht das es egal ist alles kopiert werden konnte oder nicht, das am Ende der Stick ausgeworfen werden soll‽
Warum bekommt `copy()` den Namen des Sticks? Der wird doch da gar nicht verwendet‽
Ungetestet:
Code: Alles auswählen
#!/usr/bin/env python3
import subprocess
import time
from datetime import datetime as DateTime
from pathlib import Path
import pyudev
PFAD = Path.home() / ".DruckData"
MEDIA_PFAD = Path("/media/earl/")
WECHSEL_DATEI_NAMEN = ["numbers.csv", "TB_Ausgabe_8iii.txt"]
def warte_auf_usb_stick(udev_context):
monitor = pyudev.Monitor.from_netlink(udev_context)
monitor.filter_by("block")
for device in iter(monitor.poll, None):
if "ID_FS_TYPE" in device and device.action == "add":
name_of_stick = Path(device.get("ID_FS_LABEL"))
time.sleep(2)
return name_of_stick
raise AssertionError("unreachable code")
def copy(source_path, destination_path):
text = source_path.read_text(encoding="utf-8")
destination_path.write_text(text, encoding="utf-8")
def datei_auf_stick(name_of_stick, dateipfad, timestamp):
copy(
PFAD / dateipfad,
MEDIA_PFAD
/ name_of_stick
/ dateipfad.with_name(
f"{dateipfad.stem}_{timestamp:%Y-%m-%d_%H_%M}.csv"
),
)
def datei_auf_arbeitsverzeichnis(name_of_stick, dateipfad):
copy(MEDIA_PFAD / name_of_stick / dateipfad, PFAD / dateipfad)
def auswerfen(name_of_stick):
subprocess.run(
["umount", MEDIA_PFAD / name_of_stick],
check=True,
stdout=subprocess.PIPE,
stderr=subprocess.STDOUT,
)
def main():
udev_context = pyudev.Context()
while True:
name_of_stick = warte_auf_usb_stick(udev_context)
timestamp = DateTime.now()
try:
#
# TODO Nicht direkt die lokalen Dateien überschreiben sondern erst
# alle mit temporären Namen kopieren und dann umbenennen um
# wenigstens zu versuchen zu verhindern das es nur ein teilweises
# Update gibt.
#
for dateiname in map(Path, WECHSEL_DATEI_NAMEN):
datei_auf_stick(name_of_stick, dateiname, timestamp)
datei_auf_arbeitsverzeichnis(name_of_stick, dateiname)
except OSError as error:
print("Fehler beim kopieren:", error)
#
# TODO Soll der Stick tatsächlich nur ausgeworfen werden wenn beim
# kopieren Fehler auftraten?
#
try:
auswerfen(name_of_stick)
except subprocess.CalledProcessError as error:
print(
f"Fehler {error.returncode} beim Auswerfen: {error.stdout}"
)
if __name__ == "__main__":
main()„All religions are the same: religion is basically guilt, with different holidays.” — Cathy Ladman
Okay, das ist ein Argument, das ich verstehe, ist mir auch schon passiert. Wobei ich hier in meinem Code die Gefahr nicht als besonders hoch einschätze, dass das passiert.__blackjack__ hat geschrieben: ↑Dienstag 31. März 2020, 00:13 . Besonders lustig wird so etwas wenn die globale Variable mal nicht den Wert hat, den man da eigentlich erwartet hätte.
Das merke ich...Re Datenbank: Wenn die zweite Datei nicht da ist dann ist die erste Datei eben noch nicht in der Datenbank, denn solange die Transaktion nicht durch ein commit abgeschlossen ist, sind die Änderungen für Lesezugriffe noch nicht sichtbar und können wieder zurückgerollt werden. Das ist die Funktion von Transaktionen, dass man mehrere Änderungen machen kann, die entweder in ihrer Gesamtheit in der Datenbank landen oder gar nicht. Das auf Dateiebene selbst zu programmieren ist umständlich bis unmöglich wenn es portabel sein soll.
Das mit dem commit wäre ein Vorteil. Mal sehen, vielleicht komme ich mit der Datenbank klar. Mal probieren.
Das mag vielleicht daran liegen, dass ich den Code leider nicht zeilenweise verfolgen kann wie ich das gerne täte. Das hab ich bei IDLE zumindest noch nicht entdeckt.Du packst das auswefen des Sticks immer an komische/falsche Stellen. Die Funktion die das Anstecken des Sticks erkennen soll, sollte das Anstecken des Sticks erkennen und den Namen liefern. Und nichts anderes.
Ich schreib mir dann immer die print() rein und lasse mir was ausgeben um zu verfolgen, was gemacht wird, oder halt auch nicht. Bei einigen Sachen wurde mir da an Stellen wo ich das eigentlich nach meinem Verständnis unbedingt was geben musste, bekam ich nichts. Gar nichts. (Zum Beispiel beim Versuch die Datei zu schreiben, wo du ja sagst, da krieg ich die Überprüfung quasi mitgeliefert. Wenn der Code aber gar nicht zu der Zeile geht? Wenn er ginge, müsste er dann ja auch über die print-Zeile.)
Also hab ich mir gedacht, lege ich die Überprüfung dahin wo sie mir Sinn macht, nämlich genau dann, wenn der Stick erkannt wird. Sind dann nicht beide Dateien da, kann er gleich wieder aufhören, Stick raus, weiter lauern was passiert.
Verstehe ich, wenn das jemand nachvollziehen will.Funktionsnamen sollten die Tätigkeit beschreiben die sie durchführen. `usb_ansteckerkenner()` und `auswerfer()` sind aber keine Tätigkeiten sondern eher Namen für ”Dinge”, also eher passivere Objekte. `warten_auf_usb_stick()` und `auswerfen()` wären passender.
Das wollte ich eigentlich machen und hab das auch stehen gehabt, dann kam da eine merkwürdige Fehlermeldung dass False nicht definiert ist. Wenns halt nicht wollte, dann hab ich das so probiert um mal ein Ergebnis zu haben. die Zahlenwerte werden ja direkt in der Dokumentation (oder vielleicht hab ich das auch wo anders gelesen) erwähnt.Python hat einen eigenen Datentyp für Wahrheitswerte (`bool`) mit den Werten `True` und `False`, dafür sollte man nicht die Zahlen 1 und 0 missbrauchen.
Auch ne Angewohnheit die ich von VBA hab. Da pumpe ich alles mögliche in Variablen um zu sehen, was für Werte die annehmen, was vor allem hinter den einzelnen Objekten noch alles drinsteht. In dem Editor kann man da nämlich ganz bequem ins Objektmodell kriechen und ablesen was für Eigenschaften man manipulieren oder lesen kann. Allein schon den Wert angezeigt zu bekommen ist mir oft einiges wert zum Verständnis. (drum zig Zeilen mit print)`gehts_weiter` ist überflüssig. Man muss nicht jedes Ergebnis an einen Namen binden.
Wobei ich gerade sehe das `copy()` im Falle einer nicht gefundenen Datei gar keine Ausnahme auslöst, der Aufrufer also gar keine Möglichkeit hat darauf zu reagieren wenn das der Fall ist. Die Ausnahmebehandlung dort ist keine sinnvolle Ausnahmebehandlung. Einen Fehler einfach ausgeben und dann so weiter machen als sei alles in Ordnung ist sehr selten ein sinnvoller Umgang mit Ausnahmen. Und wenn man eine Ausnahme nicht sinnvoll behandeln kann, sollte man sie an der Stelle einfach gar nicht behandeln.Das `usb_ansteckerkenner()` nicht der geeignete Ort ist um den Stick auszuwerfen sieht man auch daran das die Funktion ja den Namen zurück gibt. Wenn Du den Stick auswirfst, dann tut sie das aber nicht, sondern gibt implizit `None` zurück, was der Code an der Aufrufstelle dann versucht als Namen für den Stick zu verwenden, was natürlich zu einer weiteren Ausnahme führen wird. Was zu einem erneuten Versuch den bereits ausgeworfenen Stick erneut auszuwerfen, was wieder zu einer Ausnahme führt. Die dann das Programm beendet. Das ist alles sehr verwirrend strukturiert.
Das gibt nicht None sondern "nope" zurück und ist auch ein Überbleibsel meiner print-debuggingversuche.Das implizite `None` sollte keine Funktion zurückgeben, die mindestens eine ``return``-Anweisung enthält. Falls so eine Funktion auch `None` als Rückgabewert haben kann, dann sollte das explizit mit einem ``return None`` passieren, damit der Leser das deutlich sieht, und weiss das es Absicht ist und kein Versehen weil ein Ablaufpfad in der Funktion übersehen wurde.
Die Funktion könnte dann so aussehen:
Das verstehe ich jetzt leider nicht. Muss ich erst noch mal google, was du mit raise meinst.
Ein nacktes ``except:`` ohne konkrete Ausnahmen ist selten bis nie eine gute Idee, weil es nur wenige Möglichkeiten gibt *alle* Ausnahmen, auch solche mit denen man gar nicht rechnet, sinnvoll zu behandeln. Eigentlich nur die Ausnahme zu protokollieren und dann erneut mit einem nackten ``raise`` wieder auszulösen. Letzteres kann man nur weg lassen wenn man sicher ist, dass danach kein Code mehr ausgeführt wird der zu Folgefehlern führt.
Ja, die Frage ist berechtigt. Aber so weit habe ich in der Tat noch nicht gedacht.Bei Deinem Code erfolgt das Auswerfen des Sticks übrigends *nicht* wenn alle kopiert werden konnte. Soll das so? Ich hätte ja jetzt eher gedacht das es egal ist alles kopiert werden konnte oder nicht, das am Ende der Stick ausgeworfen werden soll‽
Der Code muss das tatsächlich noch machen und auch dann den Code mit den Schaltflächen neu starten, denn der muss ja die neuen Daten für die Beschriftung einlesen.
Danke für den Hinweis!
Vergessen rauszunehmen. Ich hatte zuerst dort den Rauswerfer-Code platziert, was aber wegen der Folgefehler natürlich in noch mehr Fehler rannte.Warum bekommt `copy()` den Namen des Sticks? Der wird doch da gar nicht verwendet‽
Funktioniert und hat mir gleich die Augen aufgemacht für einen weiteren Fehler.Ungetestet:Code: Alles auswählen
#!/usr/bin/env python3 ...
Bin nämlich bisher immer davon ausgegangen, dass die CSV-Datei aus Access in der Kodierung bei utf-8 ist. Jetzt hatte ich eine, die hat natürlich Westlich ISO..., also das was Microsoft standardmäßig rausgibt.
Das wird vermutlich so bleiben, denn inzwischen steht soweit fest, dass die Abfrage der DB wo alle Daten der Stellen die ggf. ausgedruckt werden sollen drin sind, mit einem kleinen Excel-Makro passieren soll.
Das Ding gibt aber mit Sicherheit ein csv aus das nicht Unicode ist.
Da muss ich also dann auch noch ran...
Danke für die Unterstützung!
Die Erklärungen helfen mir zu verstehen, was ich alles übersehe.
-
__blackjack__
- User
- Beiträge: 13116
- Registriert: Samstag 2. Juni 2018, 10:21
- Wohnort: 127.0.0.1
- Kontaktdaten:
@theoS: Das Sachen nicht ausgeführt werden von denen Du erwartet hast sie werden ausgeführt kann auch an der Ausnahmebehandlung liegen, zum Beispiel wenn man nackte ``except``\s verwendet die dann einfach alles behandeln, auch Tippfehler bei Namen beispielsweise.
Schrittweise durch den Code gehen kann man mit einem Debugger. Beispielsweise mit dem `pdb`-Modul aus der Standardbibliothek. Das ist aber eigentlich nicht nötig. Vor allem nicht bei so einfachem Code. Man schreibt normalerweise kleine Funktionen, die genau eine in sich geschlossene Sache machen, und testet die. Ansonsten reichen in der Regel ein paar strategisch platzierte `print()`-Anweisungen oder so etwas wie `q`- oder das `icecream`-Modul um sich Werte ausgeben zu lassen um zu überprüfen ob das die Werte sind, die man an der Stelle erwartet. Oder Logging. Das braucht man hinterher nicht unbedingt wieder zu entfernen. Für Anwendungen finde ich das `loguru`-Modul im Moment ganz nett. Damit kann man auch etwas informativere Ausnahmen ausgeben lassen und beispielsweise einen Dekorator auf die Hauptfunktion anwenden der unbehandelte Ausnahmen protokolliert.
Du könntest Dir auch mal das `trace`-Modul aus der Standardbibliothek anschauen.
Eine vorherige Überprüfung nützt Dir doch aber auch nichts wenn der Code der dann am Ende tatsächlich kopiert, gar nicht ausgeführt wird‽ Beziehungsweise wenn das was nützt, bedeutet das doch das Du entweder einen Fehler im Code hast oder den Code nicht wirklich verstehst, und einfach nur verhinderst das dieser Code ausgeführt wird. Es wäre aber besser den Code zu verstehen und eventuelle Fehler zu beheben, statt da einfach einen Bogen drum zu machen.
`False` ist immer definiert. Das ist sogar ein Schlüsselwort, das heisst man kann das auch nicht umdefinieren wie andere Namen:
Die Funktion gibt nicht "nope" zurück sondern sie gibt "nope" als Text aus und gibt dann (implizit) `None` an den Aufrufer als Rückgabewert. Und der Code der die Funktion aufruft funktioniert nur weil `None` im boole'schen Kontext ”unwahr” ist.
``raise`` ist das Gegenstück zu ``try``/``except``. Mit ``raise`` löst man Ausnahmen aus. Die müssen ja irgend wo her kommen. Und wenn nur ``raise`` ohne eine Ausnahme in einem ``except``-Block steht, dann wird die Ausnahme erneut ausgelöst die gerade in dem ``except`` behandelt wird. Und vielleicht nicht Google, sondern einfach erst einmal die Dokumentation von Python.
Schrittweise durch den Code gehen kann man mit einem Debugger. Beispielsweise mit dem `pdb`-Modul aus der Standardbibliothek. Das ist aber eigentlich nicht nötig. Vor allem nicht bei so einfachem Code. Man schreibt normalerweise kleine Funktionen, die genau eine in sich geschlossene Sache machen, und testet die. Ansonsten reichen in der Regel ein paar strategisch platzierte `print()`-Anweisungen oder so etwas wie `q`- oder das `icecream`-Modul um sich Werte ausgeben zu lassen um zu überprüfen ob das die Werte sind, die man an der Stelle erwartet. Oder Logging. Das braucht man hinterher nicht unbedingt wieder zu entfernen. Für Anwendungen finde ich das `loguru`-Modul im Moment ganz nett. Damit kann man auch etwas informativere Ausnahmen ausgeben lassen und beispielsweise einen Dekorator auf die Hauptfunktion anwenden der unbehandelte Ausnahmen protokolliert.
Du könntest Dir auch mal das `trace`-Modul aus der Standardbibliothek anschauen.
Eine vorherige Überprüfung nützt Dir doch aber auch nichts wenn der Code der dann am Ende tatsächlich kopiert, gar nicht ausgeführt wird‽ Beziehungsweise wenn das was nützt, bedeutet das doch das Du entweder einen Fehler im Code hast oder den Code nicht wirklich verstehst, und einfach nur verhinderst das dieser Code ausgeführt wird. Es wäre aber besser den Code zu verstehen und eventuelle Fehler zu beheben, statt da einfach einen Bogen drum zu machen.
`False` ist immer definiert. Das ist sogar ein Schlüsselwort, das heisst man kann das auch nicht umdefinieren wie andere Namen:
Code: Alles auswählen
In [140]: False = "x"
File "<ipython-input-140-3e3e09fca786>", line 1
False = "x"
^
SyntaxError: can't assign to keyword``raise`` ist das Gegenstück zu ``try``/``except``. Mit ``raise`` löst man Ausnahmen aus. Die müssen ja irgend wo her kommen. Und wenn nur ``raise`` ohne eine Ausnahme in einem ``except``-Block steht, dann wird die Ausnahme erneut ausgelöst die gerade in dem ``except`` behandelt wird. Und vielleicht nicht Google, sondern einfach erst einmal die Dokumentation von Python.
„All religions are the same: religion is basically guilt, with different holidays.” — Cathy Ladman
Das dachte ich mir auch, bis ich die Fehlermeldung vor mir hatte.`False` ist immer definiert. Das ist sogar ein Schlüsselwort, das heisst man kann das auch nicht umdefinieren wie andere Namen:
Da das schon spät war, hab ich da gepfuscht. Das heißt ja nicht, dass ich das nicht noch geändert hätte. Aber ich wollte wissen, ob das an der Stelle dann so klappt. (hats ja erst mal getan, meine USB-Buchse ist schon ganz ausgeleiert...)
genau deshalb würde ich den Code eben gerne zeilenweise durchgehen. Dann sehe ich ja, ob was passiert.Eine vorherige Überprüfung nützt Dir doch aber auch nichts wenn der Code der dann am Ende tatsächlich kopiert, gar nicht ausgeführt wird‽
ich werd mir mal die Sachen anschauen die du da aufgelistet hast.
(hab ja den eine oder andere Entwicklungssoftware angeschaut. Bei dem einen war so eine Funktion dabei, das langsam durchzugehen. Dummerweise hat das mit keinem meiner Codes was anfangen können.)
Das mit der Dokumentation ist auch immer so eine Sache. Da steht drin dass man da dieses und jenes machen kann. Probier ich das dann aus, stellt sich raus, dass es doch ganz anders geht.
Das ist nicht so einfach, wenn man grad einsteigt und am Anfang auch mal ein paar Erfolgserlebnisse vertragen kann.
Es ist super, dass ihr euch solche Mühe macht, den Code zu verbessern, aber leider verwirrt mich dann die (für euch!) gezeigte Vereinfachung oft. Das reicht schon, dass die ganzen Schreibweisen plötzlich umgedreht da stehen wie in der Dokumentation.
Danke jedenfalls für die Tipps!
Solch ein Kopierprogramm testet man ja auch nicht, indem man ständig USB-Sticks ein und wieder ausssteckt, sondern indem man sich sogenannte Mock-Up-Funktionen schreibt, die nur so tun.
Denn ein fehlerhaftes Lesen oder Schreiben läßt sich ja nicht so einfach durch ein- und ausstecken simulieren.
Dann überlegst Du Dir, welche Fälle alle (wirklich alle) auftreten können, also USB-Stick nicht lesbar, nicht schreibbar, Festplatte voll, fehlende Dateien, etc.
Die obere Klasse mußt Du noch so erweitern, dass sie für jeden Fehler auch noch die richtige Fehlermeldung simuliert.
Und dann kannst Du loslegen, Deine Kopierfunktion zu testen. Passendes SystemMockup erstellen, Funktion laufen lassen und prüfen, ob das Ergebnis dem erwarteten entspricht.
So eine Mockup-Klasse zu schreiben, die so etwas komplexes wie ein Dateisystem richtig simuliert, ist gar nicht so einfach. Aber auf der anderen Seite kannst Du nur so sicher sein, dass Dein Programm in jeder Situation richtig reagiert. Diese Tests sind auch keine Wegwerfware, sondern werden bei jeder Änderung des Codes nochmal durchgeführt, um sicher zu sein, dass es immer noch alle Fälle abdeckt.
Denn ein fehlerhaftes Lesen oder Schreiben läßt sich ja nicht so einfach durch ein- und ausstecken simulieren.
Code: Alles auswählen
class SystemMockup:
def __init__(self):
self.name_of_stick = 'usb'
self.files = [
PFAD / "numbers.csv"
PFAD / "TB_Ausgabe_8iii.txt"
MEDIA_PFAD / self.name_of_stick / "numbers.csv"
MEDIA_PFAD / self.name_of_stick / "TB_Ausgabe_8iii.txt"
]
self.mounted = False
def warte_auf_usb_stick(self, context):
self.mounted = True
return self.name_of_stick
def copy(self, source_path, destination_path):
if not self.mounted:
raise IOError("path not found")
if source_path not in self.files:
raise FileNotFoundError("file not found")
self.files.append(destination_path)
def auswerfen(self, name_of_stick):
if not self.mounted:
raise subprocess.CalledProcessError()
self.mounted = False
system = SystemMockup()
warte_auf_usb_stick = system.warte_auf_usb_stick
copy = system.copy
auswerfen = system.auswerfenDie obere Klasse mußt Du noch so erweitern, dass sie für jeden Fehler auch noch die richtige Fehlermeldung simuliert.
Und dann kannst Du loslegen, Deine Kopierfunktion zu testen. Passendes SystemMockup erstellen, Funktion laufen lassen und prüfen, ob das Ergebnis dem erwarteten entspricht.
So eine Mockup-Klasse zu schreiben, die so etwas komplexes wie ein Dateisystem richtig simuliert, ist gar nicht so einfach. Aber auf der anderen Seite kannst Du nur so sicher sein, dass Dein Programm in jeder Situation richtig reagiert. Diese Tests sind auch keine Wegwerfware, sondern werden bei jeder Änderung des Codes nochmal durchgeführt, um sicher zu sein, dass es immer noch alle Fälle abdeckt.
-
__blackjack__
- User
- Beiträge: 13116
- Registriert: Samstag 2. Juni 2018, 10:21
- Wohnort: 127.0.0.1
- Kontaktdaten:
Wobei man vielleicht noch `unittest.mock` aus der Standardbibliothek erwähnen sollte und `pytest` was einen IMHO „pythonischere“ Tests schreiben lässt als `unittest`, aber auch prima mit `unittest` zusammenarbeitet.
„All religions are the same: religion is basically guilt, with different holidays.” — Cathy Ladman
Das hört sich alles sehr schön an - aber das ist mir alles zu hoch im Moment.Und dann kannst Du loslegen, Deine Kopierfunktion zu testen. Passendes SystemMockup erstellen, Funktion laufen lassen und prüfen, ob das Ergebnis dem erwarteten entspricht.
Das teste ich jetzt lieber erst mal zu Fuß.
Das schaffen dann die Anwender. (besser als Microsoft kann ichs halt nicht)Du brauchst in jedem Fall eine Liste aller möglichen Probleme, die auftreten können, nur dass Du in Echt Probleme haben wirst, die alle auch hinzubekommen.
Hab mir das mal überlegt für das Anstecken des Sticks könnte das so aussehen:
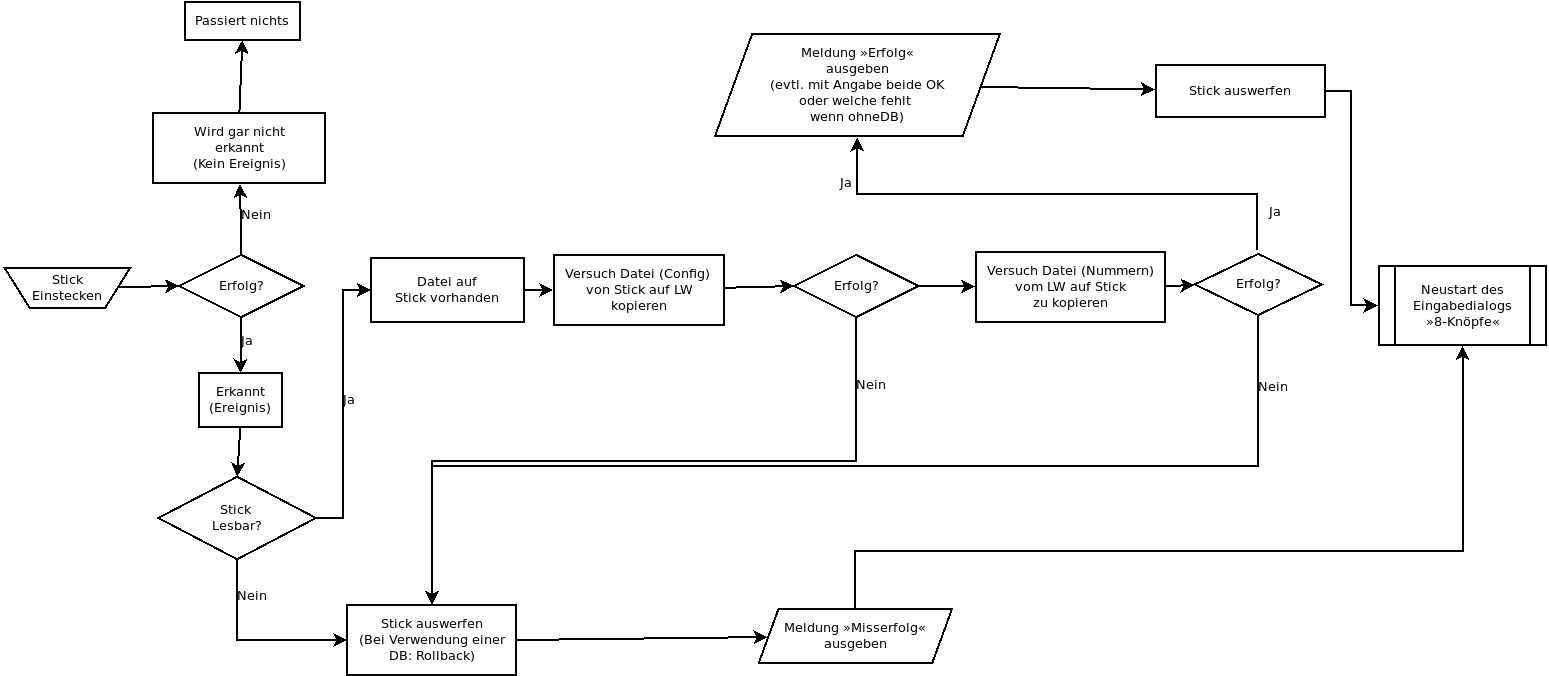
Das sollte eigentlich alles sein.
Warum es letztlich zu einem Misserfolg wird, was hier irgendwelche tiefergehenden Exceptions auslöst, sollte doch eigentlich egal sein.
Das Ergebnis soll sein: entweder/oder. Wenn dann die Config-Datei drauf ist, dann geht der Druck weiter, wenn nicht, dann noch mal ein Versuch.
Wenn das wieder nicht klappt, müssen die einfach zusehen was mit der Datei nicht stimmt. Weiteren »Support« möchte ich da programmtechnisch nicht betreiben. (Also keine Ausgabe wie »die Datei liegt leider nicht im utf-8-Format vor, speichern sie die Datei in dem Format«)
Beim Zeichnen ist mir der Einwand von __blackjack__ ziemlich genau aufgefallen. Wäre günstiger, ich hätte eine DB um dann nicht eine Hälfte zu haben und die andere nicht.
Die Nummern-Datei ist nicht ganz so wichtig, daher wäre das noch verschmerzbar, aber wenn das zurückzurollen wäre, wäre das natürlich bei weitem komfortabler.
Dabei hab ich bei meinen Experimenten festgestellt, dass ich beim Raufladen in die DB wieder ganz andere Schwierigkeiten hab.
Hier überlege ich, ob ich die Tabelle nicht einfach droppe statt einen Teil neu einzufügen und den Rest upzudaten.
(Wenn sich z.B. nur 1 Zeile ändert bzw. dazukommt)
Ist für mich momentan noch ein wenig undurchsichtig wie das bei Datenbanken so üblich ist. Bei einer csv genügt ein Öffnen mit einem Editor, bei ner DB muss ich SQL üben. (schadet ja nicht, außer meiner Faulheit...)
Ja, das ist mir klar. Dabei ist es aber denke ich komplizierter als wenn ich das in der DB mache.Den Rollback mußt Du auch für die File-basierte Lösung implementieren
Hab das jetzt mal mit Code den ich aus dem Tutorial von sqlite gefunden hab versucht überhaupt mal in eine DB zu laden. Hier ist mal ein Teilergebnis.
Fehlt noch ein ganzer Schuh, aber so könnte es gehen.
Dann mit dem commit noch warten bis alles ohne Fehler durchläuft und quasi kurz vor der "Erfolgsmeldung" erst committen.
Wenn das nicht durchgelaufen ist, habe ich ja die DB nicht verändert. Zumindest sagt mir das mein Verständnis von SQL...
Code: Alles auswählen
#!/usr/bin/env python3
# -*- coding: utf8 -*-
import sqlite3
from sqlite3 import Error
from pathlib import Path
import csv
PFAD = (Path.home() / ".DruckData")
BARCODE_DB_FILENAME = (PFAD / "sqlite/db")
CSV_DATEI = PFAD / "TB_Ausgabe_Abfrage8StueckIIII.txt"
TABELLEN = ['knopfdaten', 'numbers']
def create_connection(db_file):
conn = None
try:
conn = sqlite3.connect(db_file)
return conn
except Error as e:
print(e)
return conn
def create_table(conn, create_table_sql, tabelle):
try:
curs = conn.cursor()
# das ist vermutlich an der falschen Stelle, funktioniert aber
# sonst hatte ich einen unique constraint, umgehe damit update
curs.execute(f"DROP TABLE IF EXISTS {tabelle}")
curs.execute(create_table_sql)
except Error as e:
print(e) #das ist mal wieder was zum Abfangen, wo ich den Stick rauswerfen müsste
def lade_daten(conn):
curs = conn.cursor()
csvfile = open(CSV_DATEI, 'r')
creader = csv.reader(csvfile, delimiter=';', quotechar='"')
for t in creader:
curs.execute(f'INSERT INTO {TABELLEN[0]} VALUES (?,?,?,?,?,?,?,?,?,?,?,?,?,?,?,?,?)', t )
csvfile.close()
conn.commit() # an diese Stelle müsste ich dann noch mal ran, wenn beim Einstecke/Speichern was schiefgeht
# zum Probieren ob die Daten richtig geladen wurden
curs.execute(f"SELECT * FROM {TABELLEN[0]};")
print("fetchall:")
result = curs.fetchall()
for r in result:
print(r)
conn.close()
def main():
BARCODE_DB_FILENAME.mkdir(parents=True, exist_ok=True)
create_connection(f"{BARCODE_DB_FILENAME}/config8.db")
print(f"{BARCODE_DB_FILENAME}/config8.db")
database = f"{BARCODE_DB_FILENAME}/config8.db"
SQL_ERZEUGE_KNOPFDATEN_TABELLE = "\n".join(
[
"CREATE TABLE IF NOT EXISTS ",
TABELLEN[0],
" (ID text PRIMARY KEY,",
"E_ST text,",
"ZEILE3 text, ",
"ZEILE5 text, ",
"ZEILE6 text, ",
"ZEILE7 text, ",
"ZEILEX text, ",
"AUS_DATEI text, ",
"ISBT_NR text, ",
"HALLENPOS text, ",
"LETZTERDRUCK text, ",
"AKTUELL_NR text, ",
"BARCODE text, ",
"LZ_FARBE text, ",
"BEMERKUNG text, ",
"USER text, ",
"LETZTEAENDERUNG text); "
]
)
SQL_ERZEUGE_NUMMERN_TABELLE = "\n".join(
[
"CREATE TABLE IF NOT EXISTS ",
TABELLEN[1],
" (",
"ident integer PRIMARY KEY, ",
"knopfdaten_ID integer ,",
"anzahl_Drucke );"
]
)
conn = create_connection(database)
# Tabellen erzeugen
if conn is not None:
create_table(conn, SQL_ERZEUGE_KNOPFDATEN_TABELLE, TABELLEN[0])
conn.commit()
create_table(conn, SQL_ERZEUGE_NUMMERN_TABELLE, TABELLEN[1])
conn.commit()
else:
print("Fehler! konnte keine Verbindung zur Datenbank herstellen") # Fehlerausgabe derzeit nur für mich
if conn is not None:
lade_daten(conn) #lädt die Daten aus der csv nach
if __name__ == '__main__':
main()
@theoS: die Klammern bei der Definition von `PFAD` und `BARCODE_DB_FILENAME` sind überflüssig. Warum Du das bei der dritten Konstante schon richtig gemacht hast, bleibt wohl Dein Geheimnis.
In `create_connection` wandelst Du umständlich eine Exception in einen Rückgabewert None um, den Du dann unten zweimal explizit prüfen mußt, statt einfach dort die Exception abzufangen, wo Du etwas „sinnvolles” damit machen kannst. Dann wird `create_connection` zum Einzeiler und eigentlich überflüssig.
In `create_table` löschst Du ganze Tabellen. Das macht man nicht. Das Tabellendesign wird einmal eingelegt und nie wieder geändert. Jedenfalls nicht als Bestandteil des normalen Programmablaufs. Tabellennamen sind auch fix und werden nicht in SQL-Statements hineinformatiert.
Bei `laden_daten` öffnest Du eine Datei weder mit dem with-Statement noch mit einem expliziten Encoding. Wurde Dir hier bestimmt schon einige Male angemerkt. `creader` hört sich an, wie ein Monster aus einem Horrorfilm, `t` ist auch kein guter Name für einen Datensatz.
In `main` erzeugst Du eine Connection, wirfst sie aber gleich wieder weg! `database` ist keine Konstante. Dagegen hat `SQL_ERZEUGE_KNOPFDATEN_TABELLE` als Konstante in `main` nichts zu suchen. Das sollte auch wirklich EIN String sein, und nicht umständlich mit join erst erzeugt werden. Wie schon geschrieben, Tabellennamen sind FIX.
Zu den Tabellenspalten: Warum ist ID ein Text? Auch hier gilt, keine Abkürzungen. Was soll E_ST sein? Oder ISTB_NR? Oder LZ_FARBE? Zeile 4 fehlt, wobei eine Spalte, die Zeile heißt? Auch hier gilt, aussagekräftige Namen und keine Nummern. Gibt es auch eine AN_DATEI? Was NR (Nummer) heißt, sollte kein TEXT sein. `LETZTEAENDERUNG` sollte wohl ein Datum sein.
ID als ident abzukürzen, habe ich noch nie gesehen.
In `create_connection` wandelst Du umständlich eine Exception in einen Rückgabewert None um, den Du dann unten zweimal explizit prüfen mußt, statt einfach dort die Exception abzufangen, wo Du etwas „sinnvolles” damit machen kannst. Dann wird `create_connection` zum Einzeiler und eigentlich überflüssig.
In `create_table` löschst Du ganze Tabellen. Das macht man nicht. Das Tabellendesign wird einmal eingelegt und nie wieder geändert. Jedenfalls nicht als Bestandteil des normalen Programmablaufs. Tabellennamen sind auch fix und werden nicht in SQL-Statements hineinformatiert.
Bei `laden_daten` öffnest Du eine Datei weder mit dem with-Statement noch mit einem expliziten Encoding. Wurde Dir hier bestimmt schon einige Male angemerkt. `creader` hört sich an, wie ein Monster aus einem Horrorfilm, `t` ist auch kein guter Name für einen Datensatz.
In `main` erzeugst Du eine Connection, wirfst sie aber gleich wieder weg! `database` ist keine Konstante. Dagegen hat `SQL_ERZEUGE_KNOPFDATEN_TABELLE` als Konstante in `main` nichts zu suchen. Das sollte auch wirklich EIN String sein, und nicht umständlich mit join erst erzeugt werden. Wie schon geschrieben, Tabellennamen sind FIX.
Zu den Tabellenspalten: Warum ist ID ein Text? Auch hier gilt, keine Abkürzungen. Was soll E_ST sein? Oder ISTB_NR? Oder LZ_FARBE? Zeile 4 fehlt, wobei eine Spalte, die Zeile heißt? Auch hier gilt, aussagekräftige Namen und keine Nummern. Gibt es auch eine AN_DATEI? Was NR (Nummer) heißt, sollte kein TEXT sein. `LETZTEAENDERUNG` sollte wohl ein Datum sein.
ID als ident abzukürzen, habe ich noch nie gesehen.
Danke für den Input. Das war wie schon gesagt, ein sehr roher Entwurf. Weil ich da ja auch noch meine Fragen dazu hatte.
Die hast du ja jetzt auch gestellt.
Die Tabellen lege ich immer wieder neu an, weil ja immer nur, zumindest in der einen Tabelle, 8 Datensätze da sein dürfen. Wenn die Tabelle weg ist, ist die Gefahr dass welche übrig bleiben schon mal weg. Vermutlich gibt's einen Weg, die Rows der Tabelle zu löschen, da ich bisher auf Datensätze nur lesend zugreifen musste hab ich da noch wenig Ahnung.
Und, auch wenn es nicht schön ist, es funktioniert erst mal um weiter zu machen.
Das zweite ist das mit der ID. Die erzeugt einen Typkonflikt wenn ich die so aus der csv-Datei einlese. Weil die in der csv auch mit Anführungszeichen drin ist, was ja der Texterkenner ist. Ich bin nicht sicher, ob nicht Kommas oder Semikolen in den Daten drin ist, du siehst ja die Überschriften, die sogar in einem Fall ein Leerzeichen drin haben. (Und die ich nicht ändern kann)
Ident als Spaltenbezeichner für id ist in der DB in der ich mich lesend aufhalte Standard. Man frisst was man kennt...
Die hast du ja jetzt auch gestellt.
Die Tabellen lege ich immer wieder neu an, weil ja immer nur, zumindest in der einen Tabelle, 8 Datensätze da sein dürfen. Wenn die Tabelle weg ist, ist die Gefahr dass welche übrig bleiben schon mal weg. Vermutlich gibt's einen Weg, die Rows der Tabelle zu löschen, da ich bisher auf Datensätze nur lesend zugreifen musste hab ich da noch wenig Ahnung.
Und, auch wenn es nicht schön ist, es funktioniert erst mal um weiter zu machen.
Das zweite ist das mit der ID. Die erzeugt einen Typkonflikt wenn ich die so aus der csv-Datei einlese. Weil die in der csv auch mit Anführungszeichen drin ist, was ja der Texterkenner ist. Ich bin nicht sicher, ob nicht Kommas oder Semikolen in den Daten drin ist, du siehst ja die Überschriften, die sogar in einem Fall ein Leerzeichen drin haben. (Und die ich nicht ändern kann)
Ident als Spaltenbezeichner für id ist in der DB in der ich mich lesend aufhalte Standard. Man frisst was man kennt...
Du unterliegst einem massiven Irrtum, wenn du denkst, diese Hinweise und Massgaben waeren nur fuer "fertigen" Code. Erstens gibt es den nicht. Zweitens uebst du nicht ein, wie es richtig geht, sondern gewoehnst dir andauern an, es falsch zu machen. Aber ploetzlich legst du einen Schalter um, und alles wird gut gemacht? Wo sonst funktioniert das im Leben? Reicht fuer Stabhochsprung jetzt Mikado zu spielen?
Und natuerlich kann man Daten aus einer Datenbank loeschen. "DELETE FROM TABLE tabellenname WHERE bedingung". Wobei ich sogar deine Begruendung, es duerften nur 8 enthalten sein, in Frage stelle. Es sind immer nur 8 relevant. Das kann man aber zB so loesen, dass man immer einen neuen Eintrag macht, und den wahlweise mit einem Zeitstempel (setzt natuerlich eine funktionierende Echtzeituhr oder NTP vorraus) oder einem Zaehler versieht. Und bei der Abfrage immer nur die jeweils neuesten beruecksichtigen. Und kann somit gleich einen Verlauf fuer ein ggf. mal stattfindendes Audit oder Fehlersuche vorhalten. Vor allem aber nutzt man die Datenbank so, wie sie genutzt werden soll. Statt im Grunde nur eine milde bessere Version einer Datei anzulegen.
Und natuerlich kann man Daten aus einer Datenbank loeschen. "DELETE FROM TABLE tabellenname WHERE bedingung". Wobei ich sogar deine Begruendung, es duerften nur 8 enthalten sein, in Frage stelle. Es sind immer nur 8 relevant. Das kann man aber zB so loesen, dass man immer einen neuen Eintrag macht, und den wahlweise mit einem Zeitstempel (setzt natuerlich eine funktionierende Echtzeituhr oder NTP vorraus) oder einem Zaehler versieht. Und bei der Abfrage immer nur die jeweils neuesten beruecksichtigen. Und kann somit gleich einen Verlauf fuer ein ggf. mal stattfindendes Audit oder Fehlersuche vorhalten. Vor allem aber nutzt man die Datenbank so, wie sie genutzt werden soll. Statt im Grunde nur eine milde bessere Version einer Datei anzulegen.