Seite 1 von 1
Viele String Operationen in einem Programm - wie optimieren?
Verfasst: Donnerstag 9. Januar 2020, 09:56
von chris8080
Hallo,
ich habe ein Programm, welches aus HTML Dateien Strings extrahieren soll.
Dazu verwende ich BeautifulSoup4 in Kombination mit tonnenweise for, if, try etc.
Code: Alles auswählen
def extract_description(self, html):
soup = BeautifulSoup(str(html), 'lxml')
descr = soup.find_all('p', itemprop='description')
if len ( descr ) == 1:
return ( descr[0].getText().strip() )
descr = soup.find_all('div', class_='product--description')
if len ( descr ) == 1:
return ( descr[0].getText().strip() )
for input in soup.find_all('input', type='hidden'):
if input.name == 'description':
return (input['value'])
return (None)
Davon ca. 1200 Zeilen und das Programm wird langsam.
Gibt es eine Liste mit Prinzipien oder generell Tips wie ich hier die CPU entlasten kann?
Evtl. auch einen Hinweis, wie ich den Code insgesamt verbessern/optimieren kann.
Bisher habe ich die Optionen die möglichst häufig vorkommen in den HTML Dateien versucht weit nach oben in die Methoden zu packen.
Zusätzlich habe ich bei den for loops geschaut, ob ich welche zusammenfassen kann und dann innerhalb der loops mit mehreren ifs testen.
Und zusätzlich verwende ich bei den neuen Methoden das soup Objekt als Klassenvariable, anstelle einen HTML string per Parameter zu übergeben und soup wieder zu instanzieren.
Habt ihr Vorschläge?
Re: Viele String Operationen in einem Programm - wie optimieren?
Verfasst: Donnerstag 9. Januar 2020, 11:19
von Sirius3
Was ist `html` für ein Typ und warum wird der in einen String umgewandelt? Es sollte sich bereits um einen String handeln und dann ist die Umwandlung unnötig.
Um die Innenseiten der Klammern werden keine Leerzeichen gesetzt. Und vor allem nicht zwischen Funktionsname und Aufruf-Klammer.
Alle Returns brauchen keine Klammern. Weg damit.
Wenn Du viele Funktionen hast, die etwas aus html extrahieren, dann sollte der BeautifulSoup-Aufruf nicht innerhalb der Funktion stehen.
`getText` ist veraltet. Nimm get_text. Bei find_all kannst Du auch nach dem `name`-Attribut filtern.
So allgemeine Suchen sind sehr fehleranfällig. Versuche anhand von sicheren Kriterien die Variante der HTML-Datei zu ermitteln und suche dann nur nach der Description für diese Variante.
Re: Viele String Operationen in einem Programm - wie optimieren?
Verfasst: Donnerstag 9. Januar 2020, 11:19
von Sirius3
Um die Innenseiten der Klammern werden keine Leerzeichen gesetzt. Und vor allem nicht zwischen Funktionsname und Aufruf-Klammer.
Alle Returns brauchen keine Klammern. Weg damit.
Was ist `html` für ein Typ und warum wird der in einen String umgewandelt? Es sollte sich bereits um einen String handeln und dann ist die Umwandlung unnötig.
Wenn Du viele Funktionen hast, die etwas aus html extrahieren, dann sollte der BeautifulSoup-Aufruf nicht innerhalb der Funktion stehen.
`getText` ist veraltet. Nimm get_text. Bei find_all kannst Du auch nach dem `name`-Attribut filtern.
So allgemeine Suchen sind sehr fehleranfällig. Versuche anhand von sicheren Kriterien die Variante der HTML-Datei zu ermitteln und suche dann nur nach der Description für diese Variante.
Re: Viele String Operationen in einem Programm - wie optimieren?
Verfasst: Donnerstag 9. Januar 2020, 12:32
von __blackjack__
@chris8080: Ergänzend zu Sirius3: `input` ist der Name einer eingebauten Funktion, den sollte man nicht an etwas anderes binden.
`descr` ist eine kryptische Abkürzung der man zudem nicht ansieht, dass es sich bei dem Wert um eine Sequenz handelt.
`extract_description()` ist keine Methode. Die sollte man entweder als Funktion schreiben oder deutlich kennzeichnen, mit `staticmethod()`, dass das Absicht ist, das da eine Funktion in eine Klasse gesteckt wurde.
`find_all()` durchsucht immer das gesamte Dokument. Das ist vielleicht ein bisschen overkill wenn man eigentlich nur sicherstellen will das genau *ein* Element gefunden wird, dann kann man die Suche auf maximal 2 Treffer begrenzen.
Eine Schleife die sofort mit einem ``return`` verlassen wird ist keine Schleife. Auch hier wird wieder zu viel durchsucht, weil man ja nach dem ersten Treffer aufhören kann zu suchen.
Zwischenstand:
Code: Alles auswählen
def extract_description(html):
soup = BeautifulSoup(html, "lxml")
description_nodes = soup("p", limit=2, itemprop="description")
if len(description_nodes) == 1:
return description_nodes[0].get_text().strip()
description_nodes = soup("div", limit=2, class_="product--description")
if len(description_nodes) == 1:
return description_nodes[0].get_text().strip()
input_node = soup.find("input", type="hidden", name="description")
return input_node["value"] if input_node else None
Allgemein gilt bei so etwas das man vor dem Optimieren erst einmal Profiling betreiben sollte und nicht auf gut Glück irgendwo am Code rumschraubt.
Re: Viele String Operationen in einem Programm - wie optimieren?
Verfasst: Donnerstag 9. Januar 2020, 21:16
von chris8080
Vielen Dank euch beiden.
Vom Code Styling her sicher recht übel - ich komme von C / PHP und habe mir da ein paar Unarten angewöhnt :-S
Ich hatte in anderen Teilen des Codes auch schon angefangen mit pycodestyle - das hilft sehr gut.
Zur Optimierung bzgl. CPU Last:
Profilers hatte ich mal gehört, aber noch nie gemacht - werde mich heute damit beschäftigen.
Falls es tatsächlich nur minimal möglich ist, die Performance zu verbessern (es keine deutlich bessere Prinzipien gibt), liegt das größte "Problem" sicher lediglich in der großen Menge an HTML Dokumenten die durchlaufen werden müssen.
Re: Viele String Operationen in einem Programm - wie optimieren?
Verfasst: Sonntag 19. Januar 2020, 18:44
von chris8080
__blackjack__ hat geschrieben: Donnerstag 9. Januar 2020, 12:32
Allgemein gilt bei so etwas das man vor dem Optimieren erst einmal Profiling betreiben sollte und nicht auf gut Glück irgendwo am Code rumschraubt.
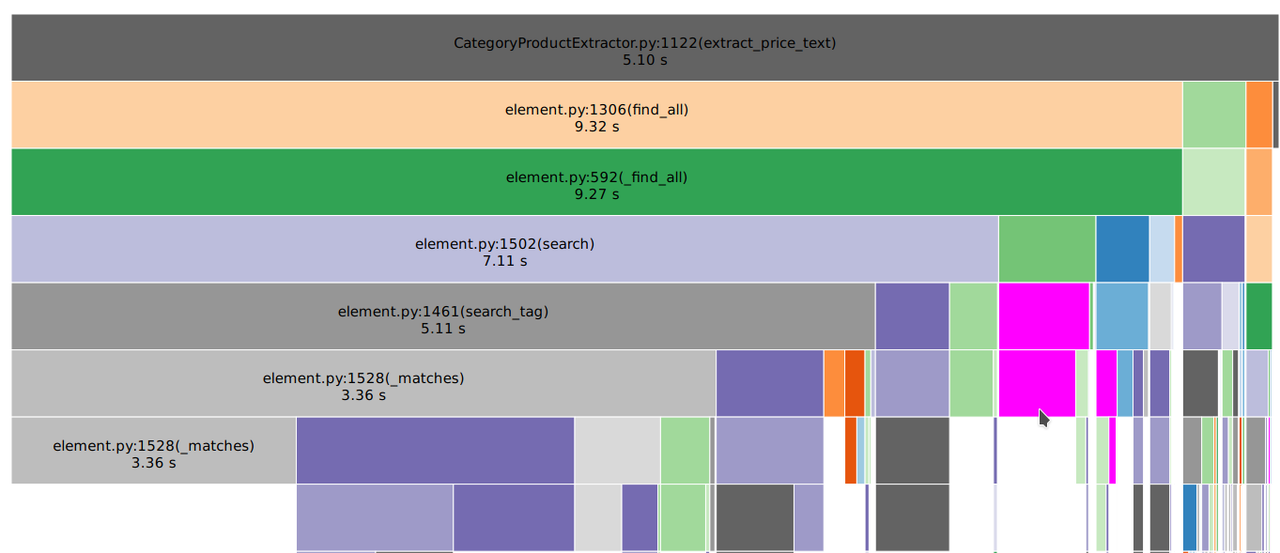
Ich habe mein script jetzt direkt mit Snakeviz genutzt und interessante Einsichten.
Die "teuerste" Methode hat eine Art "Fuzzy Search" nach dem Preis als Ziel.
Idee war: Das Skript nutzt häufig vorkommende CSS Klassennamen und extrahier alle Preis Infos in ein Array um dann später diese Ergebnisse zu vergleichen mit den konkreten Preisen. Im Idealfall bekommt man qualitativ brauchbare Daten und kann eine Art generischen exctractor nutzen.
Bisher ist die Datenqualität einigermaßen ok - noch nicht ganz brauchbar.
Was könnte man daran verbessern um CPU load zu reduzieren?
Code: Alles auswählen
def extract_price_text(self, html):
# Comment CSS classes to check for
price_css_classes = [
'element-price',
'price',
'price-info',
'product--price',
'price-box',
'producttile__price',
'price_wrapper',
'product-price',
'cat-price-container',
'current-price-container',
'product__footer',
'product__details__prices',
'PriceDivHolder',
'product-card__price',
'productBlock_link_price',
'RetailPriceValue',
'ProductDetails',
'product-block_wrapper-price',
'AdvertTile-price',
'product-listing__product__price',
]
# Use a new HTML tree since deleting branches that might be useful for other methods later on
soup = BeautifulSoup(str(html), 'lxml')
try:
soup.script.decompose()
soup.style.decompose()
except:
pass
try:
soup.script.decompose()
soup.style.decompose()
except:
pass
price_text = None
for one_css_class in price_css_classes:
# search for divs with price classes
price = soup.find_all('div', class_=one_css_class)
if len (price) >= 1:
try:
price_text = []
for one_price in price:
text = [text for text in one_price.stripped_strings]
price_text.append(text)
except:
pass
# Search for itemprop offers
if len (price) == 0:
price = soup.find_all('div', itemprop='offers')
if len (price) >= 1:
try:
price_text = []
for one_price in price:
text = [text for text in one_price.stripped_strings]
price_text.append(text)
except:
pass
# search for spans with price classes
if len (price) == 0:
price = soup.find_all('span', class_=one_css_class)
if len (price) >= 1:
try:
price_text = []
for one_price in price:
text = [text for text in one_price.stripped_strings]
price_text.append(text)
except:
price = soup.find_all('strike', class_=one_css_class)
if len (price) >= 1:
try:
price_text = []
for one_price in price:
text = [text for text in one_price.stripped_strings]
price_text.append(text)
except:
pass
return price_text
Re: Viele String Operationen in einem Programm - wie optimieren?
Verfasst: Sonntag 19. Januar 2020, 20:08
von /me
Du sprachst von einer großen Menge von HTML-Dokumenten. Da könntest du die bisher serielle Verarbeitung mit Multiprocessing parallelisieren.
Re: Viele String Operationen in einem Programm - wie optimieren?
Verfasst: Sonntag 19. Januar 2020, 22:11
von Sirius3
Naja, zuerst einmal der Kommentar zum Wiederholten parsen des gesamten HTML-Textes. Die Lösung ist, Du veränderst nie den Baum.
Nakte excepts sind blöd. Macht man nicht, ich sehe da auch nirgends eine Exception, die man einfach so ignorieren möchte.
Dann für jede Klasse alle div, span oder sonstige Elemente zu suchen, ist Verschwendung. Du gehst einmal alle Div-Elemente durch und schaust, ob irgendeine Deiner vielen Klassen da übereinstimmt. Warum Du 20 mal nach dem identischen itemprop="offers" suchen muß, wo Du doch ein Geschwindigkeitsproblem hast, weißt auch nur Du.
Vier mal den identischen Code zu der one_price-For-Schleife?
`price_text` ist gar kein Text sondern ne Liste von ner Liste und wird ständig überschrieben.
Code: Alles auswählen
PRICE_CSS_CLASSES = [
'element-price',
'price',
'price-info',
'product--price',
'price-box',
'producttile__price',
'price_wrapper',
'product-price',
'cat-price-container',
'current-price-container',
'product__footer',
'product__details__prices',
'PriceDivHolder',
'product-card__price',
'productBlock_link_price',
'RetailPriceValue',
'ProductDetails',
'product-block_wrapper-price',
'AdvertTile-price',
'product-listing__product__price',
]
def extract_price_text(self, html):
price_text = []
for tag in ['div', 'span', 'strike']:
for element in html.find_all(tag):
if not set(element['class']).isdisjoint(PRICE_CSS_CLASSES):
price_text.append(list(element.stripped_strings))
for element in html.find_all('div', itemprop='offers'):
price_text.append(list(element.stripped_strings))
return price_text