Hallo Zusammen
Ich brauche Eure Hilfe bezüglich Regex. Ich habe ein neues ecoDMS System und sollte dort den Rechnungsbetrag einlesen können.
Mit der Deutschen Schreibweise der Zahlen funktioniert dies aber leider mit der Schweizer Variante nicht.
Deutschland = 1.234,12 Thausender sind punkte und Decimal ist ein Komma
Dies ist der Code vom Hersteller
REGEX:(?<=Nettosumme:)([\s]*)\d{1,8}([\.,]\d{2})
Was ich brauche ist aber:
Schweizer = 1'234.15 Thausender sind Apostrofe und Decimal ist ein Punkt
Nettosumme: = 1'234.15
1'234.15
-1'234.15
Also Auslesen Wenn Nettosumme steht mit dem Betrag das den Betrag auslesen.
Wäre sehr dankbar wenn mir das jemand helfen könnte und mir das vielleicht ein kurz beschreiben könnte
Habe eben schon vieles Probiert auf alle arten und kriege es nicht hin.
Danke Euch
und Happy New Year
Dany
Regex
Nein, Dein regulärer Ausdruck funktioniert weder für Deutsche noch für Schweizer Schreibweise. Bei 1.234,12 ist das Ergebnis "1.23" und nicht "1.234,12". Zudem sind die Gruppen seltsam und Spaces in eine Menge zu packen, unnötig.
Wenn also beliebige Trennzeichen erlaubt sind, aber immer zwei Nachkommastellen Pflicht sind, könnte das so aussehen:
Wenn also beliebige Trennzeichen erlaubt sind, aber immer zwei Nachkommastellen Pflicht sind, könnte das so aussehen:
Code: Alles auswählen
nettosumme = re.compile("(?<=Nettosumme:)\s*([+-]?\d[\d'.,]*[.,]\d{2})")
print(re.search(nettosumme, "Nettosumme: -3'432.43").group(1))
Du denkst nur das würde für die deutsche tausender klappen - tut es aber nicht:
Und alles andere wäre auch verwunderlich - in den ersten 8 zahlen (\d{1,8}) darf gar kein Komma oder Punkt sein.
Und genau die Stelle ist die, welche du anfassen musst: statt nur Digits musst du eben digits und ' Matchen.
Achtung: ob 1—8 dann noch passt, oder ggf erweitert werden muss, musst du selbst wissen.
Und schreibt man tausend mit th in schwyzerdütsch?
Code: Alles auswählen
>>> rex = r'([\s]*)\d{1,8}([\.,]\d{2})'
>>> s = "1.234,12"
>>> re.match(rex, s)
<_sre.SRE_Match object; span=(0, 4), match='1.23'>Und genau die Stelle ist die, welche du anfassen musst: statt nur Digits musst du eben digits und ' Matchen.
Code: Alles auswählen
>>> rex = r"([\s]*)[\d']{1,8}([\.,]\d{2})"
>>> re.match(rex, s)
<_sre.SRE_Match object; span=(0, 8), match="1'234,12">Und schreibt man tausend mit th in schwyzerdütsch?
Hallo Zusammen
Danke für eure Antworten aber es geht leider noch nicht
Dies war die Hersteller Vorlage (sorry hatte die falsche vorher gepostet)
So ist ein Beispiel vom Hersteller
REGEX:([\s]*)((((\d+)[,.]{1,10})+\d{0,2})|(\d+(?!,)))
Erklärung Hersteller
Die Nettosumme in einer Rechnung soll für die Klassifizierung übernommen werden. Hierzu soll ecoDMS im Dokument nach dem Wert suchen, welcher immer hinter dem Wort "Nettosumme:" ausgegeben wird.
REGEX:(?<=Nettosumme:)([\s]*)\d{1,8}([\.,]\d{2})
Im Dokument steht zum Beispiel: Nettosumme: 289,95
Die Ausgabe für die Klassifizierung lautet bei diesem Beispiel: 289,95
(?<=Nettosumme:) sucht die Zeichenkette nach "Nettosumme:"
([\s]*) Platzhalter für ein oder mehrere Leerraumzeichen
\d{1,8}([\.,]\d{2} Platzhalter für einen durch Komma getrennten Betrag
Der Betrag den ich auslesen möchte ist 1'146.90
Zur ersten Lösung:
REGEX:(?<=CHF)\s*([+-]?\d[\d'.,]*[.,]\d{2})
Hier habe ich nur Nettosumme: durch CHF ersetzt es wird aber so nix ausgelesen

Zur zweiten Lösung:
REGEX:([\s]*)[\d']{1,8}([\.,]\d{2})
Hier habe ich jetzt nur den Betrag markiert zum auslesen und es kommt auch nix dabei raus

Mit dem Code habe ich es geschaft das aus 1'146.90 den Wert 6.90 rausgekommen ist
REGEX:([\s]*)[\d']([\.,]\d{2})
Was zu geier mache ich falsch ?
PS ja in der Schweiz schreibt man th als Thausend
Danke für eure Antworten aber es geht leider noch nicht
Dies war die Hersteller Vorlage (sorry hatte die falsche vorher gepostet)
So ist ein Beispiel vom Hersteller
REGEX:([\s]*)((((\d+)[,.]{1,10})+\d{0,2})|(\d+(?!,)))
Erklärung Hersteller
Die Nettosumme in einer Rechnung soll für die Klassifizierung übernommen werden. Hierzu soll ecoDMS im Dokument nach dem Wert suchen, welcher immer hinter dem Wort "Nettosumme:" ausgegeben wird.
REGEX:(?<=Nettosumme:)([\s]*)\d{1,8}([\.,]\d{2})
Im Dokument steht zum Beispiel: Nettosumme: 289,95
Die Ausgabe für die Klassifizierung lautet bei diesem Beispiel: 289,95
(?<=Nettosumme:) sucht die Zeichenkette nach "Nettosumme:"
([\s]*) Platzhalter für ein oder mehrere Leerraumzeichen
\d{1,8}([\.,]\d{2} Platzhalter für einen durch Komma getrennten Betrag
Der Betrag den ich auslesen möchte ist 1'146.90
Zur ersten Lösung:
REGEX:(?<=CHF)\s*([+-]?\d[\d'.,]*[.,]\d{2})
Hier habe ich nur Nettosumme: durch CHF ersetzt es wird aber so nix ausgelesen
Zur zweiten Lösung:
REGEX:([\s]*)[\d']{1,8}([\.,]\d{2})
Hier habe ich jetzt nur den Betrag markiert zum auslesen und es kommt auch nix dabei raus
Mit dem Code habe ich es geschaft das aus 1'146.90 den Wert 6.90 rausgekommen ist
REGEX:([\s]*)[\d']([\.,]\d{2})
Was zu geier mache ich falsch ?
PS ja in der Schweiz schreibt man th als Thausend
Also der hat keine Funktion weil die Wiederholung fehlt
REGEX:([\s]*)[\d']{1,8}([\.,]\d{2})
Ich weiss nicht genau wie ich das jetzt wiederholen sollte und wie oder wo ich das einbauen muss darum habe ich es einfach mal versucht
Weiss auch nicht was der + oder * {1,8} bedeuten
REGEX:([\s]*)[\d']*{1,8}([\.,]\d{2})
Fehler nicht zu wiederholen
REGEX:([\s]*)[\d']*([\.,]\d{2})
Keine Funktion
REGEX:([\s]*)[\d']+{1,8}([\.,]\d{2})
Fehler nicht zu wiederholen
REGEX:([\s]*)[\d']+([\.,]\d{2})
Keine Funktion
Ich krieg das nicht hin wie muss ich diese wiederholung erweitern
Danke dir für deine Unterstützung
Dany
REGEX:([\s]*)[\d']{1,8}([\.,]\d{2})
Ich weiss nicht genau wie ich das jetzt wiederholen sollte und wie oder wo ich das einbauen muss darum habe ich es einfach mal versucht
Weiss auch nicht was der + oder * {1,8} bedeuten
REGEX:([\s]*)[\d']*{1,8}([\.,]\d{2})
Fehler nicht zu wiederholen
REGEX:([\s]*)[\d']*([\.,]\d{2})
Keine Funktion
REGEX:([\s]*)[\d']+{1,8}([\.,]\d{2})
Fehler nicht zu wiederholen
REGEX:([\s]*)[\d']+([\.,]\d{2})
Keine Funktion
Ich krieg das nicht hin wie muss ich diese wiederholung erweitern
Danke dir für deine Unterstützung
Dany

Hier https://regexr.com kannst du mit Regular Expressions experimentieren, probieren und lernen.
Ich bin Pazifist und greife niemanden an, auch nicht mit Worten.
Für alle meine Code Beispiele gilt: "There is always a better way."
https://projecteuler.net/profile/Brotherluii.png
Für alle meine Code Beispiele gilt: "There is always a better way."
https://projecteuler.net/profile/Brotherluii.png
{kind=link}
Leg dir mal ein Testskript an, in dem du
- alle moeglichen Eingaben, die gueltig sind, als Liste von Strings drin sind.
- ueber diese Liste iterierst, und fuer jede Eingabe pruefst, ob sie funktioniert fuer einen gegebenen Ausdruck.
Das sind 10 Zeilen Code, maximal. Und dann kann man darueber auch vernuenftig reden. Niemand hier hat dein Programm zur Verfuegung, und mehr Beispiele fuer Eingaben machen das ganze auch robuster.
- alle moeglichen Eingaben, die gueltig sind, als Liste von Strings drin sind.
- ueber diese Liste iterierst, und fuer jede Eingabe pruefst, ob sie funktioniert fuer einen gegebenen Ausdruck.
Das sind 10 Zeilen Code, maximal. Und dann kann man darueber auch vernuenftig reden. Niemand hier hat dein Programm zur Verfuegung, und mehr Beispiele fuer Eingaben machen das ganze auch robuster.
Hi danyboy,danyboy hat geschrieben: ↑Dienstag 1. Januar 2019, 14:22 Zur ersten Lösung:
REGEX:(?<=CHF)\s*([+-]?\d[\d'.,]*[.,]\d{2})
Hier habe ich nur Nettosumme: durch CHF ersetzt es wird aber so nix ausgelesen
Zur zweiten Lösung:
REGEX:([\s]*)[\d']{1,8}([\.,]\d{2})
Hier habe ich jetzt nur den Betrag markiert zum auslesen und es kommt auch nix dabei raus
Mit dem Code habe ich es geschaft das aus 1'146.90 den Wert 6.90 rausgekommen ist
REGEX:([\s]*)[\d']([\.,]\d{2})
Was zu geier mache ich falsch ?
PS ja in der Schweiz schreibt man th als Thausend
auch wenn es schon etwas her ist... Ich denke, folgendes müsste funktionieren:
REGEX:(?<=CHF:)([\s]*)((((\d+)['.]{1,10})+\d{0,2})|(\d+(?!.)))
Für z.B.: CHF:111'146.90
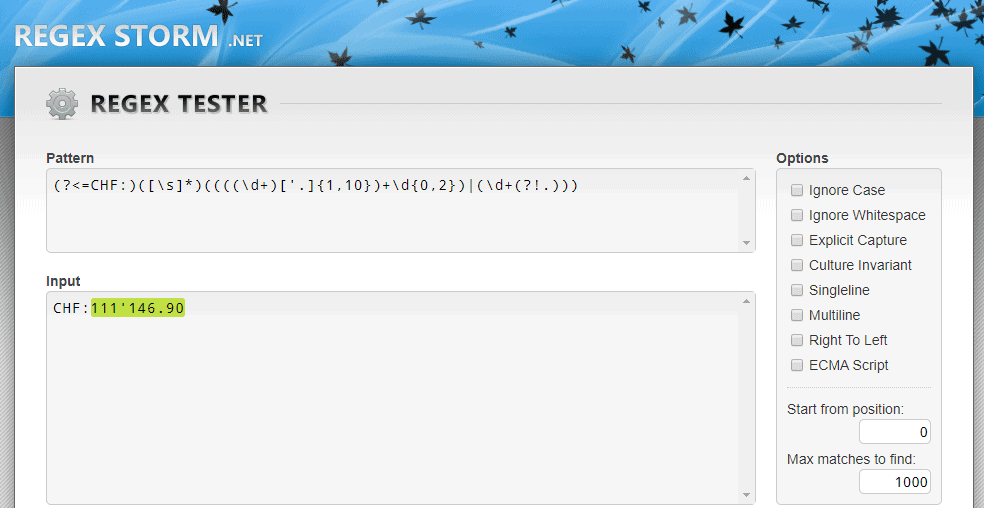
Ich werde das mal in meinem Artikel https://www.simon42.com/regex-in-vorlag ... verwenden/ ergänzen, hatte eh schon länger vor mal ein paar Snippets bereitzustellen, damit nicht jeder das Rad in ecoDMS mit eigenem Regex-gebastel neu erfinden muss
Keep on rocking und Guten Rutsch an alle
@sm2105: \s ist schon eine Zeichengruppe. Das nochmal einzeln in eine Gruppe [\s] einzuschließen ist unnötig.
Die Klammersetzung ist auch eher zufällig. Die meisten davon machen keinen Sinn.
Das mal aufgeräumt:
Dann sind die „Zahlen” die Du parsen kannst, etwas seltsam: beliebig viele Ziffern, dann 1 bis 10 Apostrophe oder Punkte? 23'..'''.'.. das soll eine Zahl sein? Und warum ist 11'146 keine gültige Zahl?
Die Klammersetzung ist auch eher zufällig. Die meisten davon machen keinen Sinn.
Das mal aufgeräumt:
Code: Alles auswählen
(?<=CHF:)\s*((\d+['.]{1,10})+\d{0,2}|\d+)-
grandpiano07
- User
- Beiträge: 2
- Registriert: Montag 6. November 2023, 18:14
Hallo Python Forum
Ich suche verzweifelt nach der Lösung in ecoDMS einen Betrag auszulesen, der mit einem Leerzeichen getrennt ist:
1 550.90
Entweder liest es nur 550.90 aus oder gar nichts. Egal wie gross der rote Auswahlbereich ist, auch wenn ich diesen nur über den Betrag selbst lege, will es nicht.
Hat jemand einen Tip, wie der Regex aussehen müsste? Das wäre grossartig.
https://www.dropbox.com/scl/fi/n1c4kamq ... db676&dl=0
Vielen Dank
Gruss
Ich suche verzweifelt nach der Lösung in ecoDMS einen Betrag auszulesen, der mit einem Leerzeichen getrennt ist:
1 550.90
Entweder liest es nur 550.90 aus oder gar nichts. Egal wie gross der rote Auswahlbereich ist, auch wenn ich diesen nur über den Betrag selbst lege, will es nicht.
Hat jemand einen Tip, wie der Regex aussehen müsste? Das wäre grossartig.
https://www.dropbox.com/scl/fi/n1c4kamq ... db676&dl=0
{kind=link}
Vielen Dank
Gruss
So gehts zb
Code: Alles auswählen
>>> import re
>>> value = '1 550.90'
>>> re.match(r'\d+\s*\d+\.\d+', value)
<re.Match object; span=(0, 8), match='1 550.90'>-
grandpiano07
- User
- Beiträge: 2
- Registriert: Montag 6. November 2023, 18:14
Vielen Dank. Ich bin total der Anfänger, daher muss ich konkreter nachfragen, was zu tun ist.
Ausgehend von dem von ecoDMS vorgegebenen REGEX-Wert (siehe nachfolgend), der mir nur den Wert "1" ausliest: Wie muss die Anpassung / Ergänzung dieser REGEX aussehen, damit es mir effektiv 1 550.90 ausliest?
REGEX:([\s]*)((((\d+)['`‘,.]{1,10})+\d{0,2})|(\d+(?!,)))
Ausgehend von dem von ecoDMS vorgegebenen REGEX-Wert (siehe nachfolgend), der mir nur den Wert "1" ausliest: Wie muss die Anpassung / Ergänzung dieser REGEX aussehen, damit es mir effektiv 1 550.90 ausliest?
REGEX:([\s]*)((((\d+)['`‘,.]{1,10})+\d{0,2})|(\d+(?!,)))
Der hier ist abgeleitet von deinem (naechstes mal gleich posten), und holt sich fuer mich zumindest den ganzen Ausdruck.
ABER: ob das klappt, haengt jetzt davon ab, wie die danach laufenden Verabeitungschritte sind. Ob der also damit klar kommt, dass da auch Leerzeichen in dem Ding vorkommen koennen. Die rauszuwerfen funktioniert naemlich nicht.
Code: Alles auswählen
REGEX:(((((\s|\d)+)['`‘,.]{1,10})+\d{0,2})|(\d+(?!,)))Wie auch schon damals angemerkt, bleibt das ein ziemlich unsinniger regulärer Ausdruck.
Wir haben jetzt beliebig viele Leerzeichen, gefolgt von bis zu 10 Apostrophen, Kommas oder Punkten und bis zu zwei Ziffern, oder beliebig viele Ziffern, wenn kein Komma folgt, ansonsten eine Ziffer weniger.
Beim ersten Beispiel ist zu beachten, dass die letzte Ziffer nicht gematched wird, beim zweiten Beispiel habe ich mich gewundert, warum trotz Komma alle Ziffern inklusive Komma gematched wird, bis ich drauf gekommen bin, dass der Fall ja schon vom ersten Oder-Ausdruck abgedeckt wird.
Wäre das nicht so, käme es zum unerwarteten Ergebnis:
Denn als letztes Zeichen darf es kein Komma geben, also wird die 3 als Ersatz genommen und eine Ziffer weniger gematched.
@grandpiano07: welche Pattern möchtest Du wirklich finden? Am besten eine Liste an Beispielen, die alle Fälle abdeckt.
Wir haben jetzt beliebig viele Leerzeichen, gefolgt von bis zu 10 Apostrophen, Kommas oder Punkten und bis zu zwei Ziffern, oder beliebig viele Ziffern, wenn kein Komma folgt, ansonsten eine Ziffer weniger.
Code: Alles auswählen
In [1]: re.match("(((((\s|\d)+)['`‘,.]{1,10})+\d{0,2})|(\d+(?!,)))", "123 23. ,'.',134")
Out[1]: <re.Match object; span=(0, 19), match="123 23. ,'.',13">
In [2]: re.match("(((((\s|\d)+)['`‘,.]{1,10})+\d{0,2})|(\d+(?!,)))", "123,")
Out[2]: <re.Match object; span=(0, 4), match='123,'>Wäre das nicht so, käme es zum unerwarteten Ergebnis:
Code: Alles auswählen
In [3]: re.match("\d+(?!,)", "123,")
Out[3]: <re.Match object; span=(0, 2), match='12'>@grandpiano07: welche Pattern möchtest Du wirklich finden? Am besten eine Liste an Beispielen, die alle Fälle abdeckt.