Vielen Dank für die Antworten

Also hier ist mein Code:
# Schritt 1: Zusammenfügen der excel Dateien der jeweiligien Gruppen aus Kurs 1.
import os
import glob
import pandas as pd
cwd = os.path.abspath('')
files = os.listdir(cwd)
file1 = "Auswertung_Proteinarray_G1.xlsx"
file2 = "Auswertung_Proteinarray_G2.xlsx"
file5 = "Auswertung_Proteinarray_G5.xlsx"
file6 = "Auswertung_Proteinarray_G6.xlsx"
df0 = pd.read_excel(file1, usecols="L")
df1 = pd.read_excel(file1, usecols="D,E")
df2 = pd.read_excel(file2, usecols="F,G")
df5 = pd.read_excel(file5, usecols="H,I")
df6 = pd.read_excel(file6, usecols="J,K")
data_frames = [df0, df1, df2, df5, df6]
df_total = pd.concat(data_frames, axis=1)
df_total.to_excel('combined_file1.xlsx')
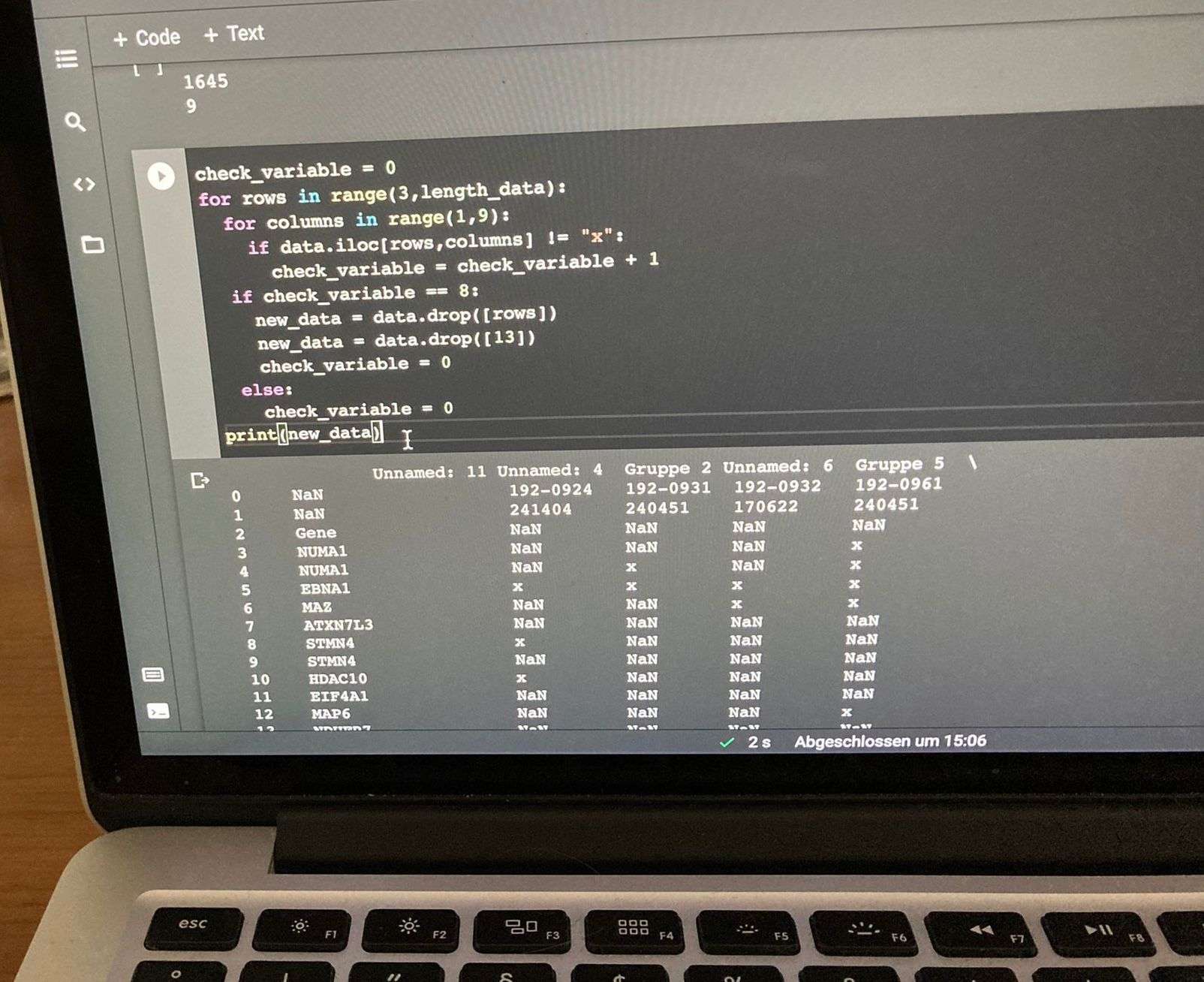
# Schritt 2: Löschen der Zeilen, welche nicht identifizierte Proteine beinhalten.
check_variable = 0
for rows in range(0, len(df_total)):
for columns in range(1, len(df_total.columns)):
if df_total.iloc[rows,columns] != "x":
check_variable = check_variable +1
if check_variable == 8:
new_data = df_total.drop([rows])
check_variable = 0
else:
check_variable = 0
Im ersten Schritt habe ich 4 .xlsx Daten in eine zusammengefasst und nun wollte ich im zweiten Schritt die unwichtigen Zeilen löschen. Also glaubt ihr, dass man mit einer for Schleife keine anständige Lösung bekommt? Sonst würde ich was anderes ausprobieren.

{kind=link}