narpfel hat geschrieben: ↑Samstag 15. Mai 2021, 18:03
@maow: `"Naphtalin0,1"` ist halt was anderes als `"Naphthalin0,01"`. Das sieht allerdings schon ein bisschen komisch aus, was du da mit `split` machst.
Ich bin Anfänger. Ja gut 0,01 0,1 wie auch immer. das schon klar, das war nur ein typo hier im Forum. Die Quintessenz kam bestimmt durch was ich gemeint hatte, und eben genau das was ich da bisher getan hatte funktioniert weiterhin nicht.
Mein allgemeines Problem ist eben eine PDF zu extrahieren. Das ist in dem Fall eben auch so, dass ich besagte .pdf auch nicht einfach so irgendwo hochladen kann, da geheim. Und ich weiß auch nix von pastebin oder schieß mich tot . Ich bin Anfänger, dass bedeutet, dass man allgemein davon ausgehen kann, dass ich am Anfang stehe, also jemand, der von diesen Dingen ansich nich viel bis gar nix weiß und dessen Code etwa so ausschaut, wie als man selbst am Anfang war

.
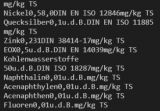
Die einzige Möglichkeit die ich aktuell habe ist es also eben euch den Screenshot zu zeigen. Meiner Meinung nach sieht man eben schon bereits in der Konsole, dass da sich was ändert. Plötzlich werden die Zeilen doch anders ausgegeben. Und sicher gibt es hier erfahrene Leute, die wissen wieso das so sein kann. Wende ich das z.B. auf Kohlenwasserstoffe an, also 'Kohlenwasserstoffe50' habe ich genau das gleiche Problem
Bei Zink0,2 geht es .. dazwischen (siehe Screenshot), irgendwo ändert sich die Consolenausgabe) - die Frage ist - wieso und wie berücksichtige ich das?
Klar, wäre ich jetzt erfahrener in Python, würde ich an all die zig Möglichkeiten denken, die man eben so hat, als Erfahrener. Dann wäre ein pastebin da, was auch immer das ist, ich hätte vielleicht diese Variable einfach in eine .txt geschrieben und mir die mal angeschaut oder so - aber ich weiß nichtmal wie sowas geht. Daher hoffe ich hier darauf, dass es hier Jemanden gibt, der ggf. Erfahrung hat und weiß woran es liegen könnte (an Stelle jetzt meinen 'komischen Code' zu hinterfragen - es ist eben Anfängercode ).
Vermutlichist es ja total einfach irgendwelche Variablen und die dazugehörigen Werte aus einer .pdf auszulesen und ihr tippt das im Schlaf runter. Bisher habe ich keine andere Lösung gefunden und die auch soweit eben erfolgreich anwenden können, daher wäre ich für Hilfe sehr dankbar.
Danke im Voraus

Hier mal kurz wie ich zu den komischen split-Dingen komme:
Code: Alles auswählen
pdfReader = PyPDF2.PdfFileReader(single_file)
pageObj = pdfReader.getPage(1)
pageObj_A = pageObj.extractText()
Also das nutze ich anfangs um mir eine bestimmte pdf.Seite geben zu lassen. Da steht nun aben viel Text und den zerschnipsel ich.