ich hab gerade folgendes Problem. Ich hab mehrere Files mit Rohdaten in einem Ordner, zum Beispiel 3 Files. Die Rohdaten sehen wie folgt aus:
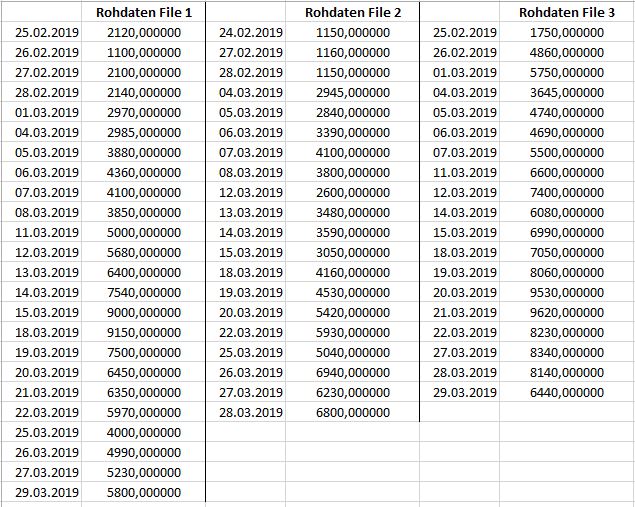
Nun möchte ich die 3 Files einlesen (zum Beispiel in eine Liste?), so dass alle 3 Listen die gleiche Anzahl Elemente haben. Wenn man die 3 Rohdaten-Files anders darstellt, ergeben sich quasi folgende Lücken, welche aufgefüllt werden müssten:
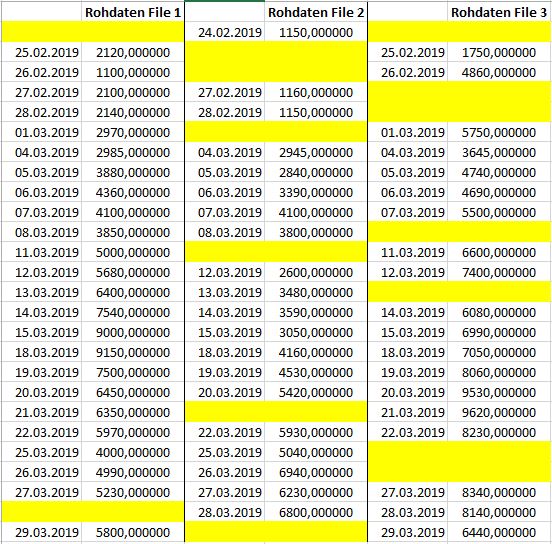
Und die Lücken sollen nun so aufgeüllt werden, dass bei einem fehlenden Datensatz der vorherige Wert eingetragen wird. Also fehlt z.B. bei File 2 der 25.02.2019, dann soll hierfür der Wert vom 24.02.2019 genommen werden. Sollte bei einem File der aller erste Wert fehlen, soll hier eine 0 eingetragen werden. Der finale Datensatz geht dann vom frühesten Datum aller Files (hier aus File 2 der 24.02.) bis zum spätesten Datum aller Files (hier aus File 1 oder 3 der 29.03.)
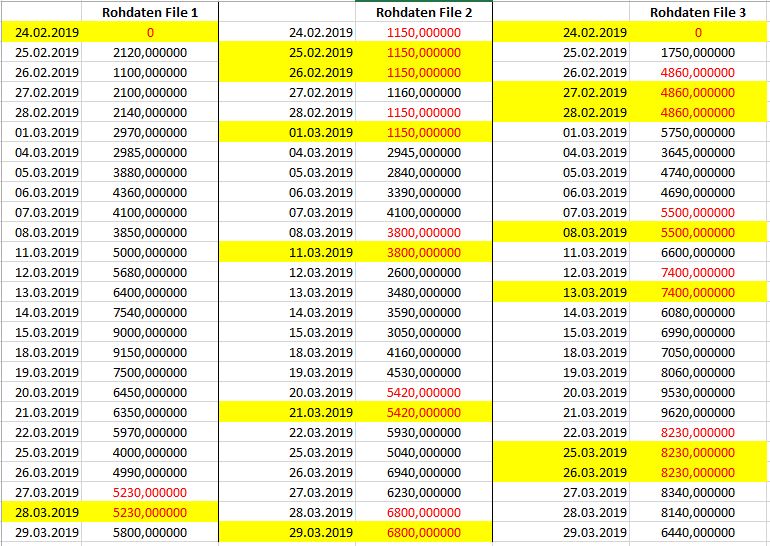
Kann mir jemand helfen?
Gruss


{kind=link}