ich habe einen Crawler geschrieben. Dieser funktioniert auch, jedoch bin ich ziemlich neu in Python und wäre froh, wenn mir jemand Verbesserungsvorschläge geben könnte.
Hier ist der Crawler: https://github.com/ford42/CrawlerHeise
Vielen Dank
LG ford

Code: Alles auswählen
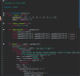
from collections import namedtuple
import requests
from bs4 import BeautifulSoup
from urllib.parse import urljoin, urlparse
CrawledArticle = namedtuple("CrawledArticle", "title, content, image, author, data, count_comments")
def get_text(post, selector, default):
element = post.select_one(selector)
return default if element is None else element.text
def parse_article(url, post):
title = get_text(post, ".tp_title", "Kein Title vorhanden!")
content = get_text(post, "p", "Kein Content vorhanden!")
author = get_text(post, "li.has-author", "Kein Autor vorhanden!")
data = get_text(post, "time", "Kein Datum vorhanden!")
count_comments = get_text(post, "span.count.comment_count", "Keine Anzahl der Kommentare vorhanden!")
img = post.select_one("img")
image = urljoin(url, img.attrs["src"]) if img is not None else "Kein Bild vorhanden!"
return CrawledArticle(title, content, image, author, data, count_comments)
def get_next_url(url, doc):
url_sub = doc.select_one(".seite_weiter")
if url_sub is not None:
return urljoin(url, url_sub.attrs["href"])
return None
def fetch_articles(url):
articles = []
while url:
r = requests.get(url)
doc = BeautifulSoup(r.text, "html.parser")
for post in doc.select("article.news.row"):
articles.append(parse_article(url, post))
url = get_next_url(url, doc)
return articles
Code: Alles auswählen
import csv
import crawler
URL = "https://www.heise.de/tp/energie-und-klima/?seite=1"
def write_to_csv(articles):
with open('articlesHeisse.csv', 'w', newline='') as csv_file:
article_writer = csv.writer(csv_file, delimiter=';', quotechar='"', quoting=csv.QUOTE_MINIMAL)
for article in articles:
article_writer.writerow(article)
def main():
write_to_csv(fetch_articles(url))
if __name__ == '__main__':
main()Code: Alles auswählen
def iter_pages(url):
while True:
doc = BeautifulSoup(requests.get(url).text, "html.parser")
yield url, doc
url_sub = doc.select_one(".seite_weiter")
if url_sub is None:
return
url = urljoin(url, url_sub.attrs["href"])
def fetch_articles(url):
for page_url, page in iter_pages(url):
for post in page.select("article.news.row"):
yield parse_article(page_url, post)