Hallo @bb1898:
Danke für Deine Hinweise. Besonders neu sind sie allerdings nicht. Dass bei Windows Vista und 7 die Codepage 850 ein quasi Standard ist, hat nicht nur Sirius3 festgestellt, auch ich habe geschrieben, dass die Umstellung von der
Standard-Codepage 850 in der Registry erfolge.
Standard ist aber eine Sache, die Realität eine andere. Wenn man zum Beispiel unter Google den Suchbegriff "
standard für windows codepage" eingibt, bekommt man an erster Stelle diesen Verweis:
Windows-1252 - Wikipedia. Auch bei den nachfolgenden Verweisen findet man noch lange keine Hinweise auf die Codepage 850.
Nach meinen Erfahrungen werden im deutschen Sprachraum Computer mit vorinstalliertem Windows in den allermeisten Fällen mit der Codepage Windows-1252 ausgeliefert. Auf zwei anderen Rechnern von mir ist diese Codepage zum Beispiel eingestellt, ohne dass ich dies explizit gemacht hätte.
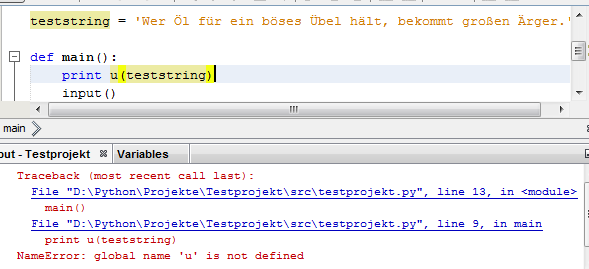
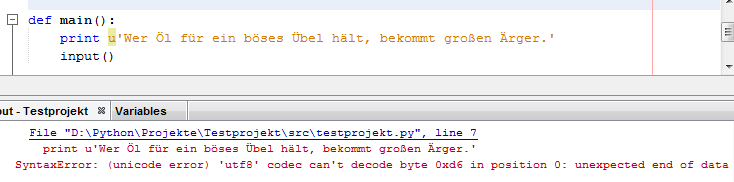
Auch die beiden von Dir vorgeschlagenen Varianten, den Ausgabestring entweder mit encode('cp850') oder dem vorangestelltem Literal "u" an die Einstellung unter Windows anzupassen, wurden hier bereits angesprochen und als gangbare Wege festgestellt. Nur ist es mir aber lieber, wenn ein Programm nicht ganz gezielt an eine Umgebung angepasst, sondern so gestaltet ist, dass es nach Möglichkeit unter allen Umgebungen funktioniert.
Neu ist also lediglich Dein Vorschlag, von Python 2 auf Python 3 umzusteigen. Nun, wegen einem Miniproblem, das sich durch eine simple Änderung in der Registry beheben lässt, auf Python 3 umzusteigen, nein, das sehe ich nicht als einen guten Vorschlag an.
MfG, kodela