Hallo,
eine gefühlte Ewigkeit versuche ich nun schon, die deutschen Sonderzeichen auch bei einer Ausgabe für die Konsole richtig dargestellt zu bekommen.
Ich bearbeite die Skripts mit NetBeans 8.0.2 und verwende im Augenblick ein Notebook mit Windows Vista.
Die Zeichencodierung kann für jedes Projekt unter NetBeans individuell eingestellt werden, aber alle meine bisherigen Versuche waren zum Scheitern verurteilt. Im Skript gebe ich in Zeile 2 zum Beispiel mit "# -*- coding: utf-8 -*-" die selbe Kodierung ein, wie ich sie Unter NetBeans für das Abspeichern eingegeben habe.
Versucht habe ich es zum Beispiel neben "utf-8" mit "iso 8859-1" oder "Windows 1251". Was ich auch einstelle, die Darstellung ist nicht korrekt. Wer kann mir helfen.
MfG, kodela
Darstellung deutscher Sonderzeichen in Konsole
Die encoding declaration am Anfang der Datei dient nur dazu da dem Interpreter zu sagen mit welchem Encoding er deine Python Datei dekodieren muss. Was die Verarbeitung von Strings angeht musst du schon selbst schauen dass du diese korrekt dekodierst und enkodierst.
Am besten du zeigst uns deinen Code.
Wenn du Hilfe willst ist es übrigens sinnvoll es möglichst einfach zu machen dir welche zu geben. Informationen hinter einem "Wer kann mir helfen" zu verstecken, schadet dir letztendlich selbst.
Am besten du zeigst uns deinen Code.
Wenn du Hilfe willst ist es übrigens sinnvoll es möglichst einfach zu machen dir welche zu geben. Informationen hinter einem "Wer kann mir helfen" zu verstecken, schadet dir letztendlich selbst.

Ist doch ganz einfach, die Ausgabe muss man stets für die Windows-Kommandozeile, die nur cp1252 versteht, kodieren. Intern rechnest du dann mit UTF-8 und die Eingabe sind dann latin1. Deinen Code speichert man dann sinnigerweise als UTF-8 ab. Für Python 3 ist das dann ein wenig einfacher aber kodieren nach cp1252 muss man immer noch.
Das ist so nicht ganz richtig. Aufgrund von Rückwärtskompatibilität muss Windows annehmen dass Anwendungen nur cp1252 verstehen und ausgeben. Man kann über die Windows API allerdings problemlos utf-16-le bekommen und ausgeben, Python macht dies nur dummerweise nicht. Das kann man aber umgehen indem man click nutzt, was seit Version 6.0 die Windows API nutzt.darktrym hat geschrieben:Ist doch ganz einfach, die Ausgabe muss man stets für die Windows-Kommandozeile, die nur cp1252 versteht, kodieren.
-
kodela
- User
- Beiträge: 185
- Registriert: Montag 12. Oktober 2015, 21:24
- Wohnort: Landsberg am Lech
- Kontaktdaten:
Hallo,
hier also ein Beispielcode:
Und damit sieht zum Beispiel die Ausgabe in der Konsole so aus:
In NetBeans habe ich dabei für das Projekt den Code "Windows-1252" eingestellt, der vermutlich mit cp1252 identisch ist.
Die Anzeige im Editor von NetBeans ist absolut korrekt.
Stelle ich in NetBeans und im Skript utf-8 ein, sieht der Code im Editor so aus:
und in der Konsole so:
Ich kann ausprobieren, was ich will, ich bekomme es nicht hin, dass der Text in der Konsole und auch im Editor richtig angezeigt wird.
@darktrym:
Danke für Deine Infos. Ich habe damit weiter experimentiert, leider aber bisher erfolglos.
@DasIch:
Auch Dir danke für Deine Antwort. Warum aber unterstellst Du mir, dass ich Informationen hinter einem "Wer kann mir helfen" verstecken will? Ist eine höfliche Frage für Dich schon Indiz genug, mir zu misstrauen? Was würdest Du sagen, wenn man Dir zum Beispiel unterstellen würde, überheblich zu sein?
Ich habe mich bemüht, die notwendigen Informationen zu liefern. Nur weil mir das vielleicht nicht gelungen ist, lasse ich mir ungern nachsagen, ich würde etwas verstecken wollen.
MfG, kodela
hier also ein Beispielcode:
Code: Alles auswählen
#!/usr/bin/env python2
# -*- coding: utf-8 -*-
def main():
print 'Wer Öl für ein böses Übel hält, bekommt großen Ärger.'
input()
if __name__ == "__main__":
main()Code: Alles auswählen
Wer Íl f³r ein b÷ses ▄bel hõlt, bekommt gro▀en ─rger.Die Anzeige im Editor von NetBeans ist absolut korrekt.
Stelle ich in NetBeans und im Skript utf-8 ein, sieht der Code im Editor so aus:
Code: Alles auswählen
Wer Öl für ein böses Ãœbel hält, bekommt großen Ärger.Code: Alles auswählen
Wer ├ûl f├╝r ein b├Âses ├£bel h├ñlt, bekommt gro├ƒen ├ärger.
@darktrym:
Danke für Deine Infos. Ich habe damit weiter experimentiert, leider aber bisher erfolglos.
@DasIch:
Auch Dir danke für Deine Antwort. Warum aber unterstellst Du mir, dass ich Informationen hinter einem "Wer kann mir helfen" verstecken will? Ist eine höfliche Frage für Dich schon Indiz genug, mir zu misstrauen? Was würdest Du sagen, wenn man Dir zum Beispiel unterstellen würde, überheblich zu sein?
Ich habe mich bemüht, die notwendigen Informationen zu liefern. Nur weil mir das vielleicht nicht gelungen ist, lasse ich mir ungern nachsagen, ich würde etwas verstecken wollen.
MfG, kodela
Das Problem ist dass du einen Byte String nutzt. Dieser String enthält die Bytes genau in der Form wie dein Editor sie abgespeichert hat. Print gibt diese unerändert an sys.stdout weiter.
Um das Problem zu lösen musst du einfach Unicode Strings benutzen.
Um das Problem zu lösen musst du einfach Unicode Strings benutzen.
Das hat nichts mit misstrauen zu tun. Ob du die Informationen auf die Weise verstecken willst oder nicht spielt auch keine Rolle, du tust es. Fragen der Form "Wer kann mir helfen" verbunden mit wenigen bis gar keinen Informationen zum Problem obwohl die offensichtlich hilfreich wären um zu helfen, begegnem einem sehr häufig. Meiner Erfahrung nach werden diese immer von Anfängern gestellt die noch nicht gelernt haben Fragen, dem Medium gerecht, sinnvoll zu stellen. Es ist ja anders als du behauptest noch nichtmal höflich. Eine solche Frage stellt man über synchrone Medien weil man jemanden die Möglichkeit geben will sich nicht zu sehr unterbrechen/stören zu lassen, dieses Problem taucht bei einem asynchronen Medium gar nicht auf. Im Gegenteil dein Gegenüber muss dir so erstmal Antworten und dann auf deine Reaktion warten um darauf die Antwort zu liefern, die man schon lange hätte machen können.Auch Dir danke für Deine Antwort. Warum aber unterstellst Du mir, dass ich Informationen hinter einem "Wer kann mir helfen" verstecken will? Ist eine höfliche Frage für Dich schon Indiz genug, mir zu misstrauen? Was würdest Du sagen, wenn man Dir zum Beispiel unterstellen würde, überheblich zu sein?
-
BlackJack
@kodela: In dem Kommentar muss die Kodierung stehen in der auch die Datei *tatsächlich* kodiert ist. Wenn Du da UTF8 schreibst, Umlaute im Quelltext stehen, und der Compiler *nicht* mit einem Kodierungsproblem abbricht, dann stimmt das sehr wahrscheinlich. Stellt sich die Frage was die „Windows-1252“-Einstellung von Netbeans dann überhaupt bewirkt…
Was dann aber wieder sehr komisch ist: Das anscheinend bei Deiner Ausgabe ein Umlaut nur durch ein (falsches) Zeichen dargestellt wird. Das kann nicht sein weil in der *Byte*kette (ist ja anscheinend Python 2) pro Umlaut *zwei* Bytes gespeichert sind, die Konsole aber eine Kodierung mit einem Byte pro Zeichen verwendet. Das kann nicht sein.
Und dann sagst Du du änderst die Einstellung im Skript (was soll *das* bedeuten?) und in Netbeans auf UTF-8 — und *dann* wird UTF8 im Editor angezeigt als würde kein UTF8 bei einer Einstellung mit einem Byte pro Zeichen angezeigt? Das kann ebenfalls nicht sein, denn dann kann der Editor nicht auf UTF8 eingestellt sein, oder Du hast da *sehr* kaputte, nämlich ”mehrfach” kodierte Daten. Da wäre dann nicht mehr die Frage wie man die vernünftig ausgegeben bekommt, sondern wie das passieren konnte.
Bei Python 2 musst Du Dir erst einmal klar machen das das hinter ``print`` da keine *Zeichen*kette im dem Sinne ist das da Zeichen drin sind. Das sind Bytes, die man als Zeichen in einer bestimmten Kodierung interpretieren kann. Und wenn man die nicht in der Kodierung interpretiert in der sie tatsächlich kodiert *sind*, dann kommen falsche Zeichen dabei heraus. Wenn die also nicht in der Kodierung vorliegen welche die Konsole erwartet, dann musst Du die erst mit der Kodierung dekodieren um ”echte” Zeichen zu bekommen und dann in der Kodierung welche die Konsole erwartet wieder zu einer Bytefolge kodieren.
Was dann aber wieder sehr komisch ist: Das anscheinend bei Deiner Ausgabe ein Umlaut nur durch ein (falsches) Zeichen dargestellt wird. Das kann nicht sein weil in der *Byte*kette (ist ja anscheinend Python 2) pro Umlaut *zwei* Bytes gespeichert sind, die Konsole aber eine Kodierung mit einem Byte pro Zeichen verwendet. Das kann nicht sein.
Und dann sagst Du du änderst die Einstellung im Skript (was soll *das* bedeuten?) und in Netbeans auf UTF-8 — und *dann* wird UTF8 im Editor angezeigt als würde kein UTF8 bei einer Einstellung mit einem Byte pro Zeichen angezeigt? Das kann ebenfalls nicht sein, denn dann kann der Editor nicht auf UTF8 eingestellt sein, oder Du hast da *sehr* kaputte, nämlich ”mehrfach” kodierte Daten. Da wäre dann nicht mehr die Frage wie man die vernünftig ausgegeben bekommt, sondern wie das passieren konnte.
Bei Python 2 musst Du Dir erst einmal klar machen das das hinter ``print`` da keine *Zeichen*kette im dem Sinne ist das da Zeichen drin sind. Das sind Bytes, die man als Zeichen in einer bestimmten Kodierung interpretieren kann. Und wenn man die nicht in der Kodierung interpretiert in der sie tatsächlich kodiert *sind*, dann kommen falsche Zeichen dabei heraus. Wenn die also nicht in der Kodierung vorliegen welche die Konsole erwartet, dann musst Du die erst mit der Kodierung dekodieren um ”echte” Zeichen zu bekommen und dann in der Kodierung welche die Konsole erwartet wieder zu einer Bytefolge kodieren.
-
kodela
- User
- Beiträge: 185
- Registriert: Montag 12. Oktober 2015, 21:24
- Wohnort: Landsberg am Lech
- Kontaktdaten:
Hallo @@DasIch:
Danke für Deinen neuerlichen Hinweis. Unsere Beiträge haben sich überschnitten. Mittlerweile habe ich Deinen Verweis auf das click-Modul gesehen und versucht, mir davon einen ersten Eindruck zu machen, glaube aber, dass ich mit diesem Modul gewissermaßen mit Kanonen auf Spatzen schießen würde. Da ist es wohl besser, für einfache Ausgaben in der Konsole auf Sonderzeichen zu verzichten. Ich dachte nur, es müsse doch möglich sein, auch über Python Texte so auszugeben, wie man sie schreibt. Das scheint aber, zumindest unter Windows, doch nicht der Fall zu sein.
MfG, kodela
PS: Eben habe ich gesehen, dass von Dir eine neue Antwort da ist. Mit dieser muss ich mich erst noch beschäftigen.
Danke für Deinen neuerlichen Hinweis. Unsere Beiträge haben sich überschnitten. Mittlerweile habe ich Deinen Verweis auf das click-Modul gesehen und versucht, mir davon einen ersten Eindruck zu machen, glaube aber, dass ich mit diesem Modul gewissermaßen mit Kanonen auf Spatzen schießen würde. Da ist es wohl besser, für einfache Ausgaben in der Konsole auf Sonderzeichen zu verzichten. Ich dachte nur, es müsse doch möglich sein, auch über Python Texte so auszugeben, wie man sie schreibt. Das scheint aber, zumindest unter Windows, doch nicht der Fall zu sein.
MfG, kodela
PS: Eben habe ich gesehen, dass von Dir eine neue Antwort da ist. Mit dieser muss ich mich erst noch beschäftigen.
-
kodela
- User
- Beiträge: 185
- Registriert: Montag 12. Oktober 2015, 21:24
- Wohnort: Landsberg am Lech
- Kontaktdaten:
Hallo BlackJack,BlackJack hat geschrieben:...Und dann sagst Du du änderst die Einstellung im Skript (was soll *das* bedeuten?) und in Netbeans auf UTF-8 — und *dann* wird UTF8 im Editor angezeigt als würde kein UTF8 bei einer Einstellung mit einem Byte pro Zeichen angezeigt? Das kann ebenfalls nicht sein, denn dann kann der Editor nicht auf UTF8 eingestellt sein, oder Du hast da *sehr* kaputte, nämlich ”mehrfach” kodierte Daten. Da wäre dann nicht mehr die Frage wie man die vernünftig ausgegeben bekommt, sondern wie das passieren konnte.
Bei Python 2 musst Du Dir erst einmal klar machen das das hinter ``print`` da keine *Zeichen*kette im dem Sinne ist das da Zeichen drin sind. Das sind Bytes, die man als Zeichen in einer bestimmten Kodierung interpretieren kann. Und wenn man die nicht in der Kodierung interpretiert in der sie tatsächlich kodiert *sind*, dann kommen falsche Zeichen dabei heraus. Wenn die also nicht in der Kodierung vorliegen welche die Konsole erwartet, dann musst Du die erst mit der Kodierung dekodieren um ”echte” Zeichen zu bekommen und dann in der Kodierung welche die Konsole erwartet wieder zu einer Bytefolge kodieren.
danke für Deine Antwort. Mit "Einstellung im Skript" ist die Codierungsangabe in der zweiten Zeile gemeint, also zum Beispiel "# -*- coding: ISO-8859-1 -*-". Die Einstellung in NetBeans bewirkt, so weit ich dies beurteilen kann, die tatsächliche Codierung, welche für den Editor benutzt wird. Bei vielen, aber nicht allen Änderungen kommt diese Meldung: "Changing project encoding might result in some characters in existing files not being read and written correctley."
Die Situation, dass für ein Sonderzeichen bei der Ausgabe in der Konsole auch nur ein (falsches) Zeichen steht, gilt, wie ich geschrieben und nochmal überprüft habe, wenn ich unter NetBeans als Code "Windows-1252" und im Skript "utf-8" verwende. Ändere ich in NetBeans die Einstellung auf "utf-8", dann werden bei der Ausgabe für die Konsole aus einem zwei Zeichen ("Wer Öl für ein böses Ãœbel hält, bekommt großen Ärger."). Die Anzeige im Editor ist immer noch korrekt. Ich habe auch keine sehr kaputte Daten, denn sie wurden von mir für den jetzigen Test noch einmal neu eingetippt.
Dass unter Python 2 die Zeichen eines Strings standardmäßig als Bytfolge codiert sind, ist mir klar. Ich gehe auch davon aus, dass die Konsole unter Windows entweder auf den Code "cp 1252" eingestellt ist oder sich einstellen lässt. Damit werden die Sonderzeichen korrekt dargestellt. Wie die Codierung allerdings genau aussieht, weiß ich nicht, werde das aber morgen einmal ergründen. Vielleicht hilft mir das weiter. Im Augenblick bin ich zu müde, um mich mit dieser Sache noch weiter vernünftig zu beschäftigen.
Eigenartig ist, dass mir dieses Problem in so hartnäckiger Weise bisher noch nicht untergekommen ist.
MfG, kodela
-
Hyperion

- Moderator
- Beiträge: 7478
- Registriert: Freitag 4. August 2006, 14:56
- Wohnort: Hamburg
- Kontaktdaten:
Hast Du das Script denn wirklich einmal manuell in einer Command Shell gestartet? Oder nur über die IDE?
encoding_kapiert = all(verstehen(lesen(info)) for info in (Leonidas Folien, Blog, Folien & Text inkl. Python3, utf-8 everywhere))
assert encoding_kapiert
assert encoding_kapiert
@kodela:
Dein Code oben sieht aus, als passen weder Editor-Encoding, Pythonsource-Encoding noch das Konsolen-Encoding zusammen. Ich kenne NetBeans nicht, daher weiss ich nicht, wie der Editor da tickt. Prinzipiell musst Du unter folgende Encodings scheiden:
- Editor-Encoding: Sind die Bytes, welche der Editor in die Datei legt. IdR sind Input- und Outputencoding gleich (bei manchen Editoren separat einstellbar), daher sollte ein ö ein ö bleiben mit erneutem Öffnen.
- Pythonsource-Encoding: Das ist der "coding: ...." String, um Python zu sagen, welches Encoding vorliegt. Das sollte mit dem Editorencoding übereinstimmen, sonst kommt da Käse raus. (Dein Editor zeigt dann zwar ein ö an, Python interpretiert das aber gar nicht als ö).
- Konsolen-Encoding: Das, was die Konsole als Bytes erwartet bzw. darstellen kann. Früher war das unter Windows cp850, inzwischen ist das auch umstellbar auf Unicode (UTF16).
Interessant wirds, wenn Du eine Datei mit Umlauten bereits hast und im Editor das Encoding plötzlich umstellst. Wenn der Editor die bereits vorhandenen Umlaute dann nicht rekodiert, entstehen seltsame Mischkodierungen und die Datei ist kaputt. Das sieht man häufiger unter Windows.
UTF8 ist unter unixoiden System inzwischen Quasistandard, weshalb eigentlich alle Editoren das auch als Standard setzen und man nur noch selten diese Encoding-Verrenkungen machen muss. Unter Windows ist das leider nicht der Fall.
Dein Code oben sieht aus, als passen weder Editor-Encoding, Pythonsource-Encoding noch das Konsolen-Encoding zusammen. Ich kenne NetBeans nicht, daher weiss ich nicht, wie der Editor da tickt. Prinzipiell musst Du unter folgende Encodings scheiden:
- Editor-Encoding: Sind die Bytes, welche der Editor in die Datei legt. IdR sind Input- und Outputencoding gleich (bei manchen Editoren separat einstellbar), daher sollte ein ö ein ö bleiben mit erneutem Öffnen.
- Pythonsource-Encoding: Das ist der "coding: ...." String, um Python zu sagen, welches Encoding vorliegt. Das sollte mit dem Editorencoding übereinstimmen, sonst kommt da Käse raus. (Dein Editor zeigt dann zwar ein ö an, Python interpretiert das aber gar nicht als ö).
- Konsolen-Encoding: Das, was die Konsole als Bytes erwartet bzw. darstellen kann. Früher war das unter Windows cp850, inzwischen ist das auch umstellbar auf Unicode (UTF16).
Interessant wirds, wenn Du eine Datei mit Umlauten bereits hast und im Editor das Encoding plötzlich umstellst. Wenn der Editor die bereits vorhandenen Umlaute dann nicht rekodiert, entstehen seltsame Mischkodierungen und die Datei ist kaputt. Das sieht man häufiger unter Windows.
UTF8 ist unter unixoiden System inzwischen Quasistandard, weshalb eigentlich alle Editoren das auch als Standard setzen und man nur noch selten diese Encoding-Verrenkungen machen muss. Unter Windows ist das leider nicht der Fall.
-
kodela
- User
- Beiträge: 185
- Registriert: Montag 12. Oktober 2015, 21:24
- Wohnort: Landsberg am Lech
- Kontaktdaten:
Ja, ich habe es über die IDE von NetBeans, aber auch direkt über die Konsole gestartet. Hier eine Kopie davon:Hyperion hat geschrieben:Hast Du das Script denn wirklich einmal manuell in einer Command Shell gestartet? Oder nur über die IDE?
Code: Alles auswählen
D:\Python\Projekte\Testprojekt\src>dir
Datenträger in Laufwerk D: ist Daten
Volumeseriennummer: 363C-0D1E
Verzeichnis von D:\Python\Projekte\Testprojekt\src
28.11.2015 09:00 <DIR> .
28.11.2015 09:00 <DIR> ..
27.11.2015 18:24 685 setup.py
30.11.2015 01:45 255 testprojekt.py
2 Datei(en), 940 Bytes
2 Verzeichnis(se), 131.111.391.232 Bytes frei
D:\Python\Projekte\Testprojekt\src>python testprojekt.py
Wer Íl f³r ein b÷ses ▄bel hõlt, bekommt gro▀en ─rger.
Hier noch ein Bild, wie das in der IDE von NetBeans aussieht:
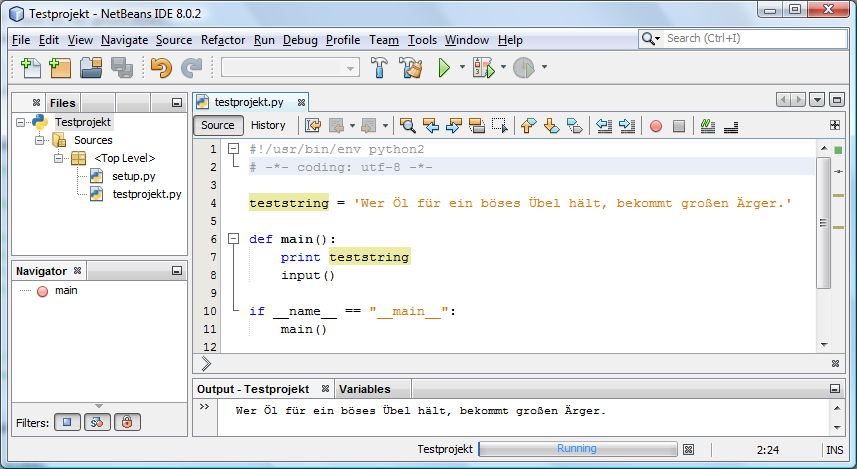
MfG, kodela
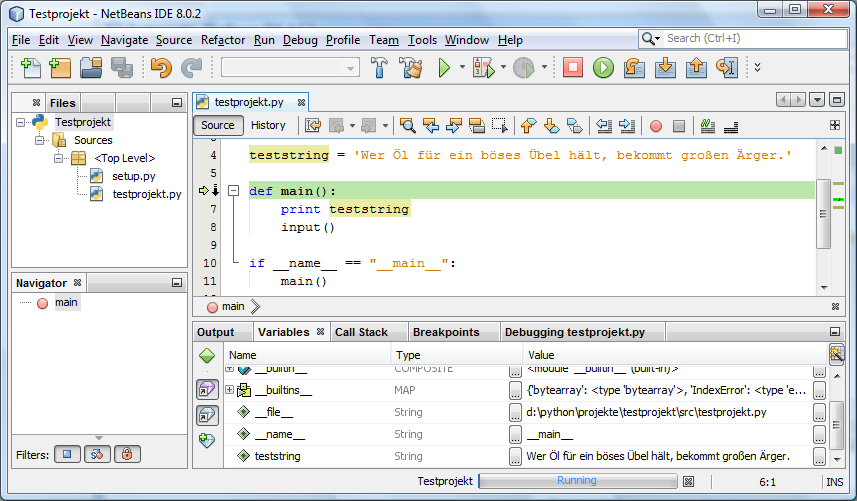
-
kodela
- User
- Beiträge: 185
- Registriert: Montag 12. Oktober 2015, 21:24
- Wohnort: Landsberg am Lech
- Kontaktdaten:
Hallo,
ich weiß nicht, ob es von Bedeutung ist, aber ich habe den Text mit den Sonderzeichen in die Konsole geschrieben, davon eine Kopie gemacht und diese in einer Textdatei gespeichert.
Ein Vergleich mit einem Hex-Editor der Textstelle in dieser Datei und der in der py-Datei, die von NetBeans gespeichert wurde, ergab völlige Identität.
MfG, kodela
ich weiß nicht, ob es von Bedeutung ist, aber ich habe den Text mit den Sonderzeichen in die Konsole geschrieben, davon eine Kopie gemacht und diese in einer Textdatei gespeichert.
Ein Vergleich mit einem Hex-Editor der Textstelle in dieser Datei und der in der py-Datei, die von NetBeans gespeichert wurde, ergab völlige Identität.
MfG, kodela
-
BlackJack
@kodela: Das ist nicht von Bedeutung weil das davon abhängt in welcher Kodierung Du den Text gespeichert hast. Das war dann einfach die gleiche wie bei der anderen Datei. Woher der Text dabei kopiert wurde ist völlig egal.
@kodela: hättest Du tatsächlich eine UTF-8 kodierte Datei, würde das hier erscheiben:
Standardmäßig ist für die CMD-Shell CP850 eingestellt. Würdest Du in Deinem Editor tatsächlich dieses Encoding einstellen, würdest Du das erhalten:
Nur wenn Du im Editor CP1252 einstellst, bekommst Du das von Dir gezeigte Bild:
Die Lösung ist, einen Unicode-String per print auszugeben. Dann wird automatisch ins Ausgabe-Encoding der shell konvertiert:
ergibt:
Komischerweise prüft python nicht, ob bei '# -*- coding: utf-8 -*-' die Datei tatsächlich utf-8-kodiert ist, so dass es völlig egal ist, was da steht, solange man keine Unicode-Strings benutzt.
Code: Alles auswählen
c:\TEMP>python x.py
Wer ├ûl f├╝r ein b├Âses ├£bel h├ñlt, bekommt gro├ƒen ├ärger.Code: Alles auswählen
c:\TEMP>python x.py
Wer Öl für ein böses Übel hält, bekommt großen Ärger.Code: Alles auswählen
c:\TEMP>python x.py
Wer Íl f³r ein b÷ses ▄bel hõlt, bekommt gro▀en ─rger.Code: Alles auswählen
# -*- coding: utf-8 -*-
print u'Wer Öl für ein böses Übel hält, bekommt großen Ärger.'Code: Alles auswählen
c:\TEMP>python x.py
Wer Öl für ein böses Übel hält, bekommt großen Ärger.-
BlackJack
Wobei die Lösung mit den Unicode-Literalen bzw. generell Unicode-Objekte per ``print`` ausgeben nur so lange eine Lösung ist, wie es Python möglich ist die erwartete Kodierung (richtig) zu raten. Wenn das letzte Beispiel ``c:\TEMP>python x.py > output.txt`` oder ``c:\TEMP>python x.py | more`` lauten würde, bekäme man eine Ausnahme statt der Ausgabe.
-
kodela
- User
- Beiträge: 185
- Registriert: Montag 12. Oktober 2015, 21:24
- Wohnort: Landsberg am Lech
- Kontaktdaten:
@Sirius3:
Danke für Dein Hilfe, aber ... siehe selbst:
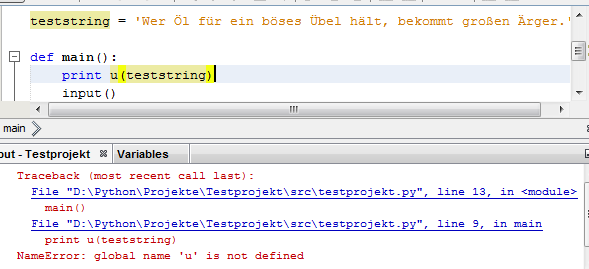
und auch:
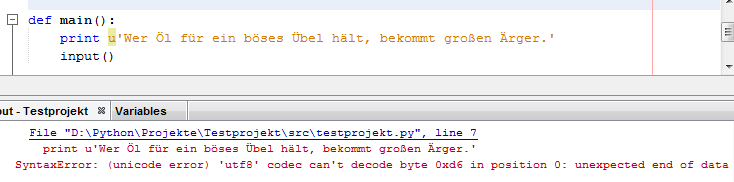
Ich habe die explizite Deklaration eines Unicode-Strings auch schon versucht.
Auch
bringt keinen Erfolg.
MfG, kodela
Danke für Dein Hilfe, aber ... siehe selbst:
und auch:
Ich habe die explizite Deklaration eines Unicode-Strings auch schon versucht.
Auch
Code: Alles auswählen
teststring = u'Wer Öl für ein böses Übel hält, bekommt großen Ärger.'MfG, kodela
-
BlackJack
@kodela: Der Kodierungsfehler kommt weil oben in der Datei offenbar im Coding-Kommentar UTF8 steht, das aber nicht stimmt. Wurde ja schon mal gesagt: In dem Kommentar muss die Kodierung angegeben werden in der die Datei auch tatsächlich kodiert ist.
-
kodela
- User
- Beiträge: 185
- Registriert: Montag 12. Oktober 2015, 21:24
- Wohnort: Landsberg am Lech
- Kontaktdaten:
Hallo @BlackJack:
Danke! Langsam bin ich am Durchdrehen. Ok, UTF-8 stimmt nicht, aber was zum Teufel stimmt dann? Wie kann ich das herausfinden?
Wenn ich den Coding-Kommentar entferne, bekomme ich ja auch einen Fehler:
"SyntaxError: Non-ASCII character '\xd6' in file D:\Python\Projekte\Testprojekt\src\testprojekt.py on line 9, but no encoding declared; see http://www.python.org/peps/pep-0263.html for details"
MfG, kodela
Danke! Langsam bin ich am Durchdrehen. Ok, UTF-8 stimmt nicht, aber was zum Teufel stimmt dann? Wie kann ich das herausfinden?
Wenn ich den Coding-Kommentar entferne, bekomme ich ja auch einen Fehler:
"SyntaxError: Non-ASCII character '\xd6' in file D:\Python\Projekte\Testprojekt\src\testprojekt.py on line 9, but no encoding declared; see http://www.python.org/peps/pep-0263.html for details"
MfG, kodela