Das hilft mir jetzt nicht EyDu, da ich nicht verstehe WO.
nomen = re.compile(r'[A-ZÄÖÜ][a-zöäü]+')
Sucht ja jedes Wort, wo die 1. Buchstabe groß ist. Soweit, so gut.
Nun möchte ich aber zusätzlich noch, dass er dabei Wörter mit max. 2 Buchstaben (So, Ab, An, Am) bzw. 3 (Als, Dem, Den, Der, Die, Das) überspringt.
Klar fallen dabei auch Nomen Ruß, Sex, Aal, Aas, aber die sind vernachlässigbar.
Ich möchte also nomen = re.compile(r'[A-ZÄÖÜ][a-zöäü]+') erweitern. Geht das? Oder muss ich einen neuen Ausdrück formulieren?
Ich dachte an r'[A-ZÄÖÜ]{4,}[a-zöäü]+' aber das scheint nicht zu gehen. Wie du siehst, ich kapier die schreibweise der reg. Ausdrücken überhaupt nicht

Edit:
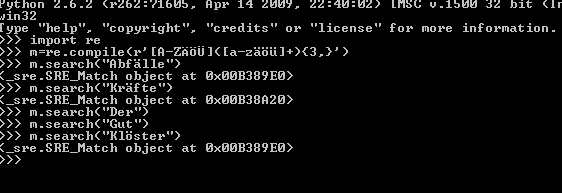
Okay, r'[A-ZÄÖÜ][a-zöäü]{3,}' funktioniert schon viel besser. Allerdings auch nicht ganz richtig.
Es werden zwar 2 und 3 Buchstabige Wörter gefiltert, aber auch:
Abfälle, Abfällen, Klänge, Klöster, Komödie, Kräfte, etc.
Wenn ich mir das richtig anschaue, alle Wörter die mehr als 3 Buchstabe haben, aber das 3. oder 4. Buchstabe ein äöüß ist, wird rausgeworfen.