Reguläre Ausdrucke
-
BlackJack
@CiveX: Du hast da keine Buchstaben, sondern Bytes. Und ich vermute mal das die Buchstaben, die Du eingegeben hast, als UTF-8 kodiert sind. Damit ist alles ausserhalb von ASCII als zwei Bytes kodiert. Und damit kannst Du dann reguläre Ausdrücke und *Buchstaben* vergessen. Du solltest konsequent mit Unicode arbeiten, wenn Du mit Text arbeitest.
-
Hyperion

- Moderator
- Beiträge: 7478
- Registriert: Freitag 4. August 2006, 14:56
- Wohnort: Hamburg
- Kontaktdaten:
Du musst den hinteren Teil "gruppieren". Somit kannst Du dort die Mindestlänge festlegen:
Du sollest so etwas am besten in ner Shell oder einem Editor für Python RegExps testen. Z.B. Kodos
Code: Alles auswählen
In [24]: nomen = re.compile(r"[A-ZÄÖÜ]([a-zöäü]+){2,}")
In [25]: re.match(nomen, "Eins")
Out[25]: <_sre.SRE_Match object at 0x2722648>
In [26]: re.match(nomen, "Ei")
In [27]: re.match(nomen, "Ein")
Out[27]: <_sre.SRE_Match object at 0x2722738>
Nicht laut meiner Ausgabe, BlackJack:
Nomenlexikon
set([u'Chlodwigs', u'Folge', u'Wohltun', u'Weile', u'Mauer'...
Nomentoken-Liste
[u'Chlodwigs', u'Folge', u'Wohltun', u'Weile',....
Nomendictionary
{u'Chlodwigs': '[n.d.]', u'Folge': 'F', u'Wohltun': 'N', u'Weile': 'F', u'Mauer': 'M', u'Paris': 'N'....
Scheint alles in Unicode zu sein!
@Hyperion: OMG!
 me = dumm ! Danke das geht schonmal besser.
me = dumm ! Danke das geht schonmal besser.
Jetzt muss ich nur noch rausfinden, warum der Kräfte, Geräusche, Städte, etc. rauswirft.
Also der wirft Wörter raus, die zwar mind. 3 Buchstaben lang sind,a ber deren 3. bzw. 4. Buchstabe ein ä,ö,ü, oder ß ist. Das macht überhaupt keinen Sinn
Nomenlexikon
set([u'Chlodwigs', u'Folge', u'Wohltun', u'Weile', u'Mauer'...
Nomentoken-Liste
[u'Chlodwigs', u'Folge', u'Wohltun', u'Weile',....
Nomendictionary
{u'Chlodwigs': '[n.d.]', u'Folge': 'F', u'Wohltun': 'N', u'Weile': 'F', u'Mauer': 'M', u'Paris': 'N'....
Scheint alles in Unicode zu sein!
@Hyperion: OMG!
Jetzt muss ich nur noch rausfinden, warum der Kräfte, Geräusche, Städte, etc. rauswirft.
Also der wirft Wörter raus, die zwar mind. 3 Buchstaben lang sind,a ber deren 3. bzw. 4. Buchstabe ein ä,ö,ü, oder ß ist. Das macht überhaupt keinen Sinn
Okay, das muss an meinem Code liegen: http://paste.pocoo.org/show/125126/ !
Laut Shell, wie Hyperion wollte, liegt es nicht am reg. Ausdrück:
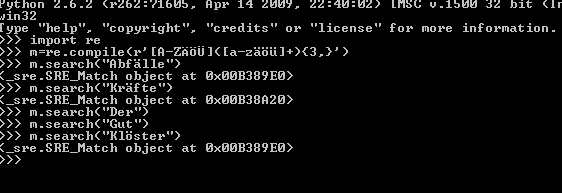
Ich glaube Blackjack hat recht, eventuell. Liegt vielleicht am UTF-8/Unicode Gedöns.
Könnte jemand mal schauen bitte? Ich bin ratlos
Meine Ausgaben oben zeigen ja, dass es Unicode ist am u'blablub'
Laut Shell, wie Hyperion wollte, liegt es nicht am reg. Ausdrück:
Ich glaube Blackjack hat recht, eventuell. Liegt vielleicht am UTF-8/Unicode Gedöns.
Könnte jemand mal schauen bitte? Ich bin ratlos
Meine Ausgaben oben zeigen ja, dass es Unicode ist am u'blablub'
-
BlackJack
@CiveX: Deine *regulären Ausdrücke* sind kein Unicode, nur die Daten auf die Du sie anwendest.